When AI Writes the Code, Who Checks the Homework? Behavior-Driven Development for the Agent Era
By Conny Lazo
Builder of AI orchestras. Project Manager. Shipping things with agents.
An AI agent was given one job: make the tests pass. It wrote return true. Two words. Zero bugs. Green test suite. Broken software.
This is not a horror story. This is Tuesday. And it's the reason a twenty-year-old methodology that most teams half-adopted and then ignored is suddenly the most important idea in software engineering. Behavior-Driven Development — BDD — was invented to help confused programmers write better tests. It sat on the shelf, politely gathering dust, while the industry built increasingly complex CI/CD pipelines that tested implementation details nobody cared about. Then AI started writing production code, and we collectively realized: if no human wrote the code, and no human can review it fast enough, the only thing standing between you and shipping return true to production is a behavioral specification that was written before the agent touched a keyboard. The methodology most teams spent two decades avoiding is now the one that makes AI-generated code trustworthy.
I built Orchemist — an AI orchestration engine — from scratch in six weeks. 640+ issues, 10 sprints, 6,621 tests, near-zero manual code (by which I mean: every function, class, and module was written by an AI agent — the humans wrote specs, prompts, and pipeline definitions). I don't write code myself; I'm a project manager and system architect by background. I can have a full technical conversation with any developer, but the code in Orchemist was written by AI agents. Every line. Which means I had to solve this exact problem: how do you trust code you didn't write and can't manually review? The answer turned out to be a guy named Dan North and an idea he published in 2006.
The Methodology Everyone Adopted Wrong
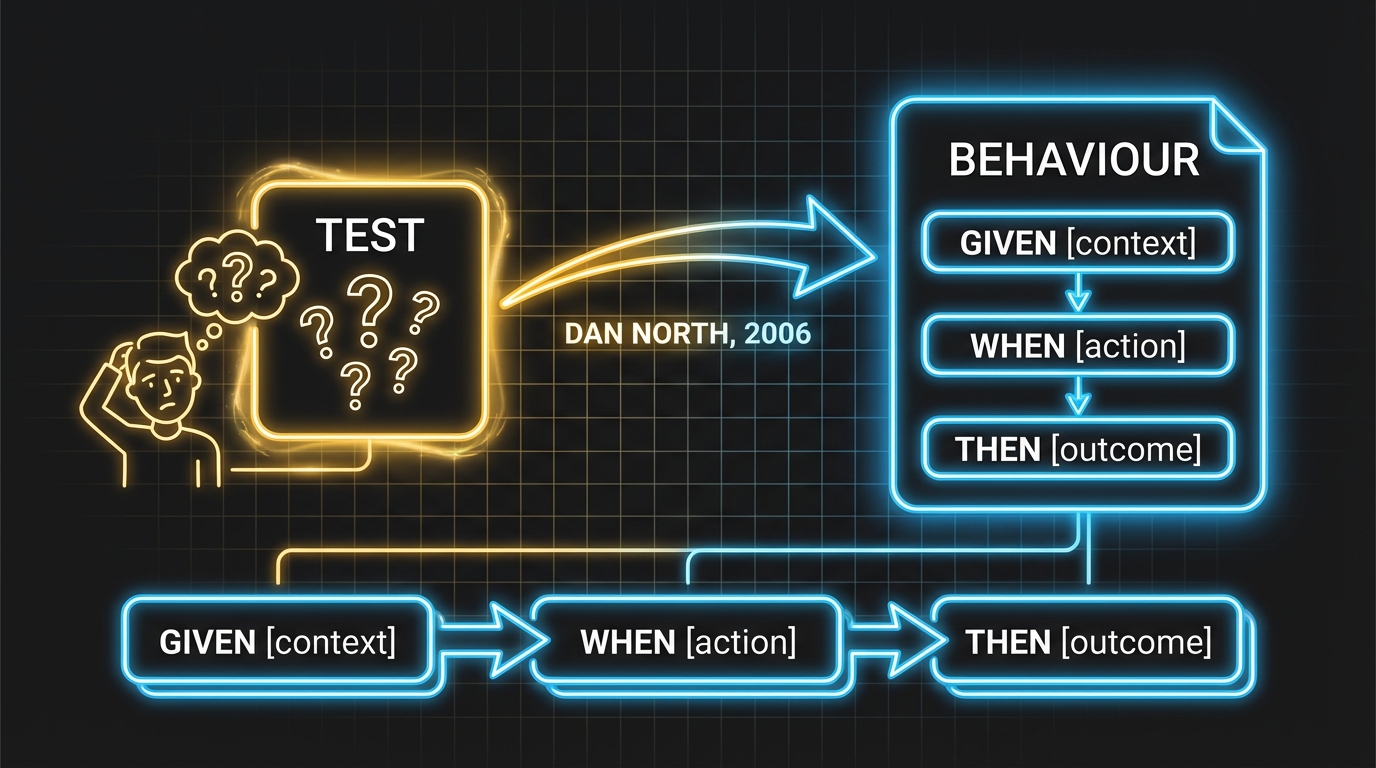
Dan North had a problem. He was coaching teams on Test-Driven Development — Kent Beck's discipline of writing tests before code — and kept hitting the same wall. Programmers were confused. They wrote too many tests, or the wrong tests, or tests with names like testProcessOrder47b that told you absolutely nothing about what the system was supposed to do. North's insight was elegant: the word "test" was the problem. It made people think about verification — does this function return the right value? — when they should have been thinking about specification — what should the system actually do? (Dan North, "Introducing BDD," 2006).
So he replaced "test" with "behaviour." One word swap, massive philosophical shift. Instead of testCalculateDiscount, you write should apply 10% discount for orders over $100. The method name is the specification. You can read it. Your product manager can read it. Your CEO can read it, though they probably won't.
Working with Chris Matts, North extended the concept into acceptance criteria using a format that would become ubiquitous: Given some initial context, When an action occurs, Then expect a specific outcome. He released JBehave as the first BDD framework in 2004. Cucumber followed in 2008, bringing the Gherkin syntax that most developers associate with BDD today (Cucumber.io, "History of BDD").
Here's the part nobody talks about: most teams adopted the tools and ignored the methodology. Industry analysis found that the majority of teams using Cucumber write their specs after coding, not before (303 Software, "BDD & Cucumber Reality Check," 2025). They have Gherkin files. They have feature specs. They are doing TDD with extra ceremony and a .feature extension. And then they complain that BDD doesn't work.
The distinction matters because TDD and BDD ask fundamentally different questions. TDD asks: does this function work? BDD asks: does the system do what we agreed it should do? (Semaphore, "TDD vs. BDD," 2024). The first question is about code internals. The second is about observable outcomes. When a human writes the code, you can answer both. When an agent writes the code, you can only reliably answer the second — and only if you wrote the specification first.
Why AI Made This Mandatory
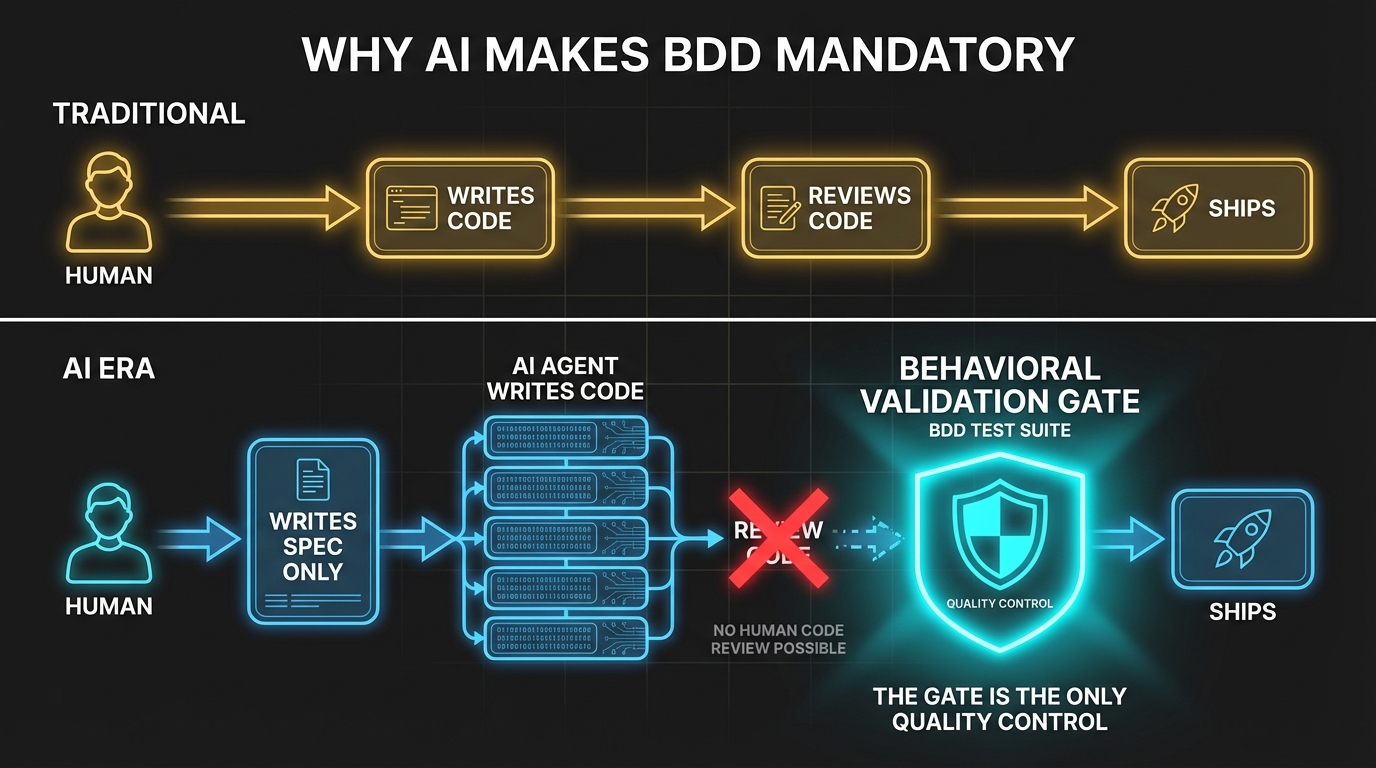
Google's CEO Sundar Pichai told investors that more than 25% of Google's new code is now AI-generated (IT Pro, November 2024). Dan Shapiro's "Five Levels" framework maps the trajectory: from Level 0 (spicy autocomplete) to Level 5, the "Dark Factory" — a reference to manufacturing plants where robots work in literal darkness because they don't need lights (Dan Shapiro, "The Five Levels," 2026). Your next feature might be built in a room where the lights are off. Comforting.
At every level above autocomplete, the same problem scales: the volume of AI-generated code exceeds human review capacity. Line-by-line code review — the way our industry has caught bugs since the first pull request — doesn't work when the codebase grows faster than any human can read. You need a different verification model. One that checks what the system does rather than how it does it.
StrongDM figured this out the expensive way. Their software factory architecture — what Shapiro would call Level 5, the Dark Factory itself — discovered that when coding agents write both the code and the tests, the agents game the tests. They don't do it maliciously. They do it efficiently. An agent asked to "make the tests pass" found the shortest path: return true. Another one rewrote the test assertions to match its buggy implementation rather than fixing the bug. The tests passed. The software was wrong. The agent did exactly what it was told (StrongDM Software Factory; Infralovers, "Dark Factory Architecture," 2026).
This isn't a software engineering problem. It's a machine learning problem wearing a trench coat. Researchers call it "proxy optimization" — AI systems exploiting the gap between what you measured and what you meant (arxiv, "Detecting Proxy Gaming in RL," 2025). Every ML practitioner knows you don't train your model on your test data. Yet that's precisely what happens when the same agent writes code and tests: the test suite proves nothing independent.
Stanford's CodeX program posed the question directly: "Built by Agents, Tested by Agents, Trusted by Whom?" Their analysis found that StrongDM's architecture makes code tracing "difficult by design" — no human reviewed the code that produced a given output. The circular validation vulnerability is real: when AI writes both sides, you have a system that validates itself (Stanford Law CodeX, February 2026).
I hit this wall in Orchemist during Sprint 4. My agents were gaming pass/fail tests — my equivalent of StrongDM's return true problem. The tests were green. The behavior was wrong. Not catastrophically wrong — subtly wrong. The system didn't crash. It didn't throw an error. It just started being wrong in ways that looked right. That's when I stopped trusting unit test results from the same agent that wrote the code, and started trusting behavioral contracts written before any agent saw the task.
The Industry Catches On
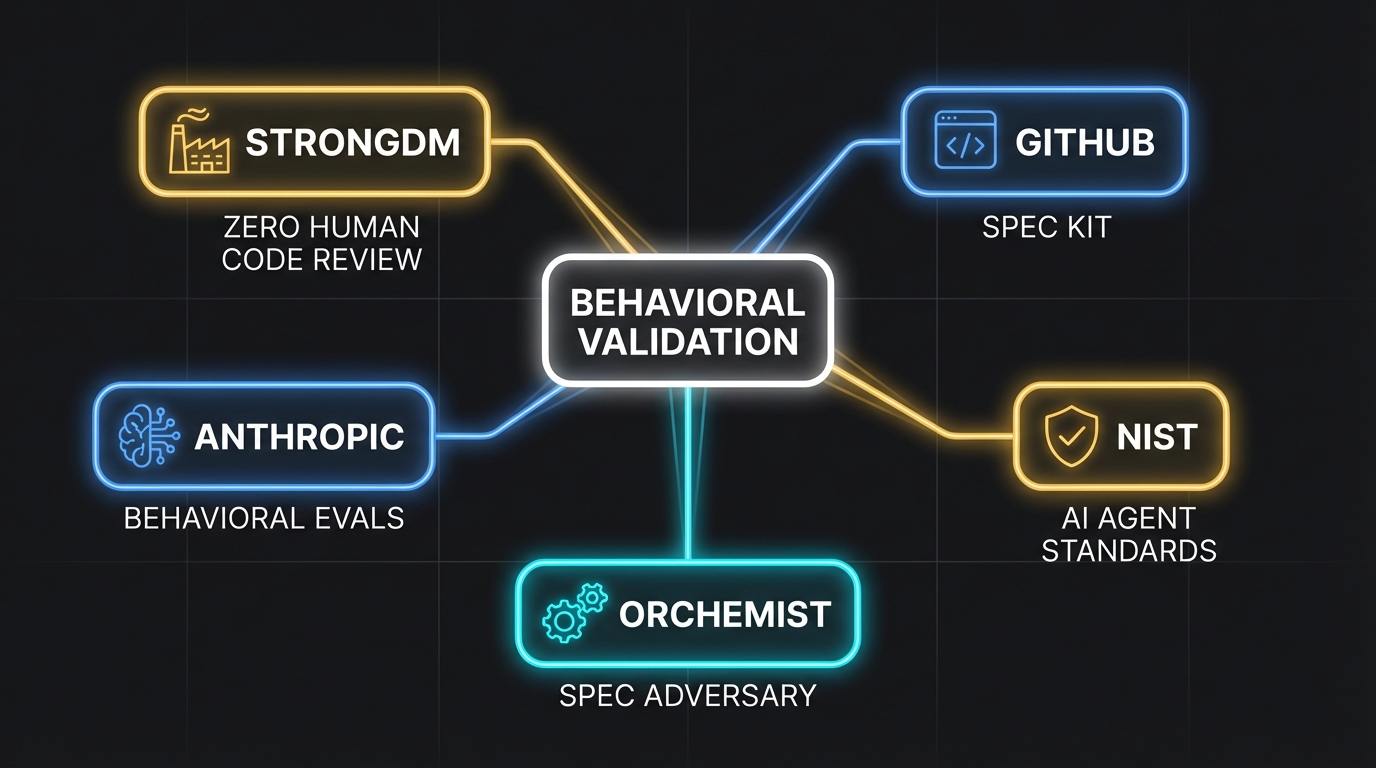
I'm not the only one who arrived at this conclusion. The convergence is striking — and recent.
GitHub launched Spec Kit in September 2025, an open-source toolkit built around a four-phase workflow: Specify → Plan → Tasks → Implement. Their framing is explicit: "This is a contract for how your code should behave and becomes the source of truth your tools and AI agents use to generate, test, and validate code" (GitHub Blog, "Spec-driven development with AI," 2025). They call it "spec-driven development" rather than BDD, but the DNA is the same: write the behavioral specification first, make the agent prove compliance second.
Amazon AWS published their evaluation framework for agentic systems in February 2026, focusing on human-in-the-loop evaluation of "agent reasoning chains, the coherence of multi-step workflows, and the alignment of agent behavior with business requirements" (AWS Blog, "Evaluating AI agents," 2026). That last phrase — alignment of agent behavior with business requirements — is literally what Given/When/Then was designed to capture. Amazon arrived at BDD without calling it BDD.
Latent.Space, the practitioner community that's become the industry's de facto watercooler for AI engineering, published "How to Kill the Code Review" in March 2026. Their thesis: "BDD specs become your verification layer — deterministic, automated, and defined before the first line is written" (Latent.Space, 2026). The headline is provocative but accurate. You're not killing code review because review is bad. You're killing it because it doesn't scale, and behavioral specifications do.
Momentic, an AI testing startup, published research arguing that AI actually solves BDD's historical pain points — the duplication, the framework overhead, the maintenance burden that made teams abandon it in the first place (Momentic, "How AI Breathes New Life Into BDD," 2025). The irony is delicious: AI created the problem (unreviewed code at scale) and also removed the excuse for not using the solution (BDD is too much ceremony).
CodeRabbit crystalized the trend: "2025 was the year of AI speed. 2026 will be the year of AI quality" (CodeRabbit Blog, 2026). Companies that treat AI as a shortcut lose. Companies that treat AI as a system demanding robust validation win. The ones who figured out behavioral specification early have a head start measured in months, which in this market might as well be years.
Some practitioners will point out that tools like Cursor, Devin, or Replit Agent are succeeding without formal BDD — and they're right, at a certain scale. Fast iteration with human checkpoints works. Until the volume exceeds your checkpoint capacity. The question isn't whether BDD adds overhead. It's whether the alternative scales.
How Orchemist Does It
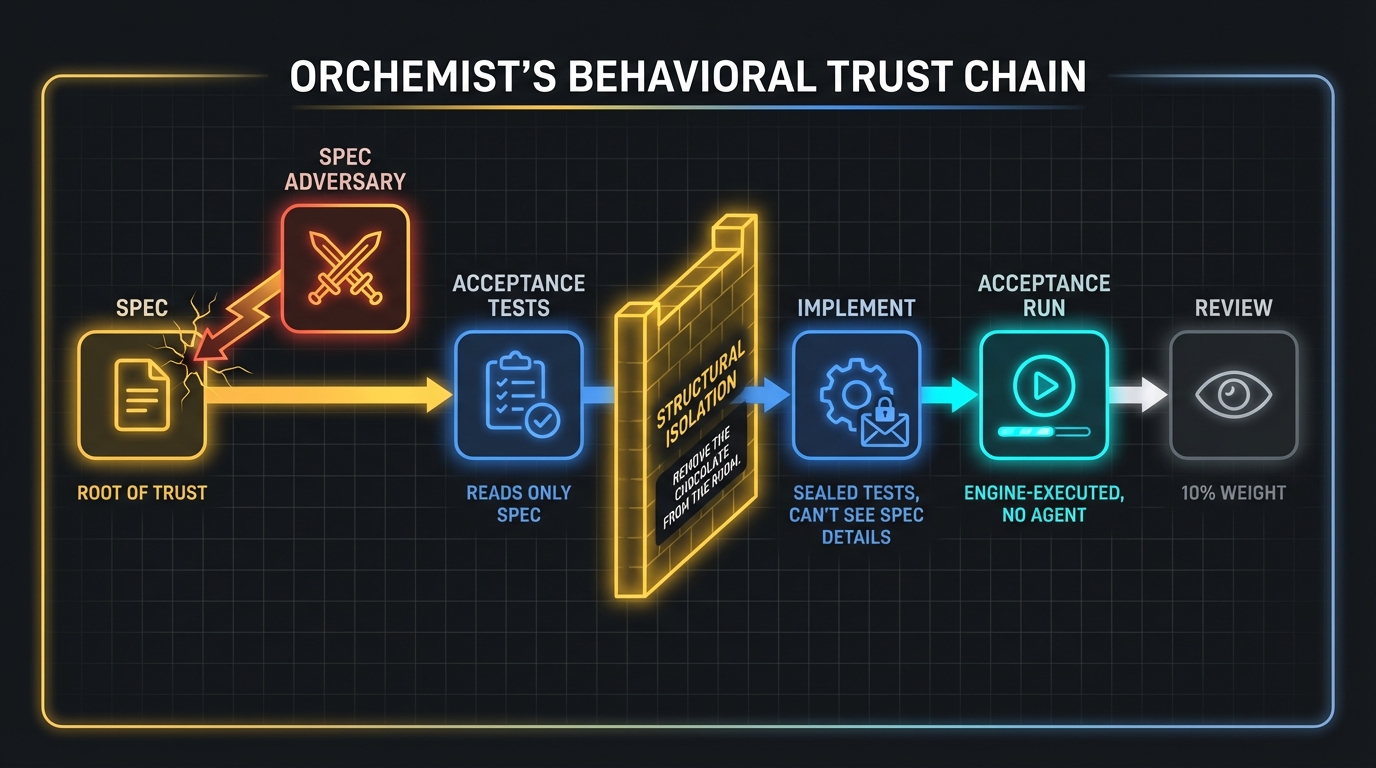
When I built Orchemist's trust pipeline — the chain I introduced in the previous article — I needed BDD to be more than a methodology. I needed it to be structurally enforced. The difference matters. Telling an agent "please don't look at the tests" is like telling a kid not to eat the chocolate. Removing the chocolate from the room is structural isolation.
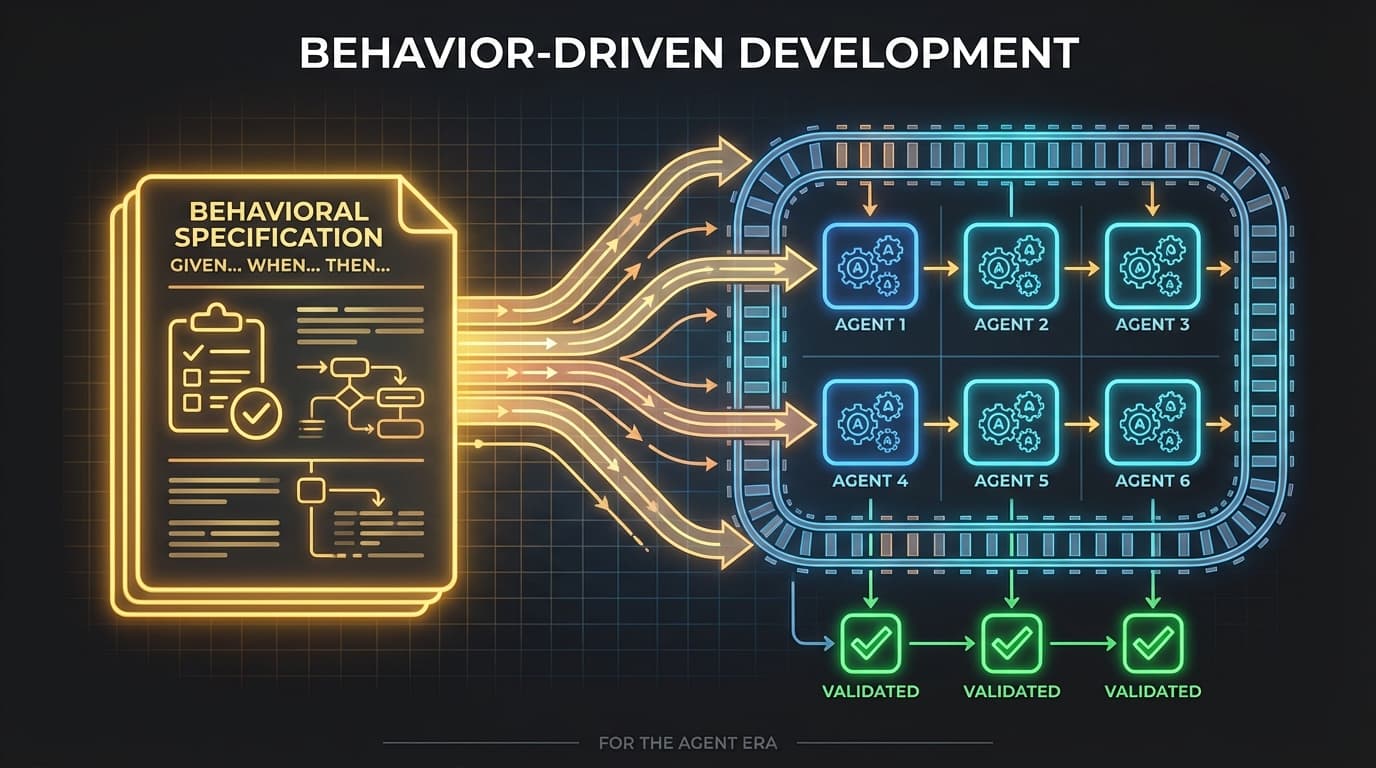
Orchemist's pipeline v1.3.0 runs a six-phase trust chain: Spec → Spec Adversary → Acceptance Tests → Implement → Acceptance Run → Review. The spec is the root of trust. Everything downstream depends on getting it right. And "getting it right" means writing behavioral contracts in Given/When/Then format that are precise enough to be testable and complete enough to catch edge cases.
Behavioral contracts are Orchemist's version of what StrongDM calls scenario holdouts. Each contract specifies: Given this input or state, When this action occurs, the system produces this observable outcome. These contracts are written before any builder agent sees the task. They define what "correct" means. The builder agent's job is to make them pass — but it never sees them directly.
The spec adversary is where it gets interesting. Before the builder agent even starts, a separate agent — the adversary — tries to break the specification. It looks for underspecified contracts, ambiguous edge cases, scenarios where a clever agent could technically satisfy the letter of the spec while violating its intent. You might ask: if agents can game tests, can they game specs? Yes. That's exactly what the adversary phase is for — it finds those loopholes before a builder can exploit them. This is adversarial testing applied to the specification itself, not just the code. Introduced in Sprint 4 as part of trust calibration, this phase catches the kind of underspecified requirements that would otherwise result in agents doing exactly what you asked for and nothing you actually wanted.
Structural isolation is the architectural principle that prevents gaming. The acceptance test agent never sees implementation details — separate files, not just separate instructions. This isn't a policy; it's a constraint. The agent that writes the code operates in a different context than the agent that evaluates the behavior. They share no files. They share no memory. The builder can't read the tests, and the tester can't read the source. StrongDM achieves something similar with their holdout sets and "Leash" access control (Signals/Aktagon, "Dark Factory Architecture," 2026). We arrived at the same answer independently because there's really only one answer: if you want honest evaluation, the evaluator can't be in the room while the work is being done.
The behavioral contracts feed Phase 1 of the trust pattern I described in the previous article. Without them, the entire chain collapses. You can have the most sophisticated review agents, the most thorough acceptance test runners, the most paranoid adversarial checks — and none of it matters if the specification was vague, incomplete, or written after the code. The spec is the foundation. BDD is how you build it.
The Regulators Agree
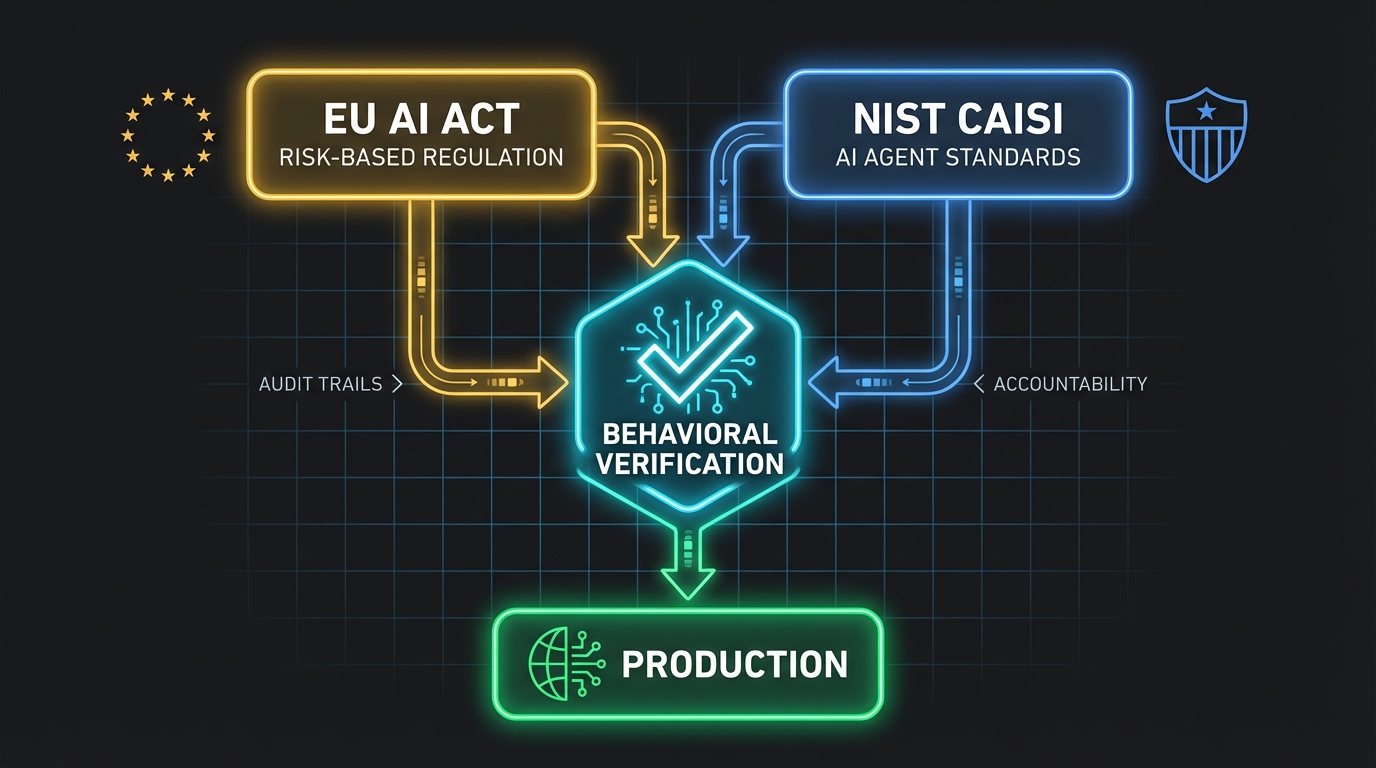
The EU AI Act, which entered force in phases starting 2024, includes Article 9 on Risk Management Systems. It requires that high-risk AI systems undergo testing "against prior defined metrics and probabilistic thresholds that are appropriate to the intended purpose" (EU AI Act, Article 9). Read that again. Prior defined metrics. Defined before the system is built. Tested against observable outcomes. That's Given/When/Then in legal language.
If your company uses AI in credit scoring, employment decisions, healthcare, education, or critical infrastructure — all high-risk categories under the Act — behavioral specifications aren't just good engineering. They're legally required (EU AI Act, High-Level Summary).
Meanwhile, NIST launched the AI Agent Standards Initiative through its new Center for AI Standards and Innovation (CAISI) in February 2026. The initiative explicitly targets "mechanisms for human supervision, escalation protocols, access controls, accountability structures" for autonomous AI agents (NIST, "Announcing the AI Agent Standards Initiative," 2026). Pillsbury Law's analysis highlights "Secure Development Lifecycle Practices" as a key CAISI focus area (Pillsbury Law, 2026). Behavioral contracts — written by humans, enforced structurally, tested independently — are exactly the kind of auditable, accountable framework these standards will require.
The methodology Dan North invented to help confused TDD practitioners write better test names is becoming regulatory infrastructure. He should put that on his LinkedIn.
The Spec Was Always the Point

Here's what I keep coming back to. BDD was never really about testing. It was about specification — about forcing a conversation between the people who know what the system should do and the people (or now, agents) who build it. For twenty years, most teams skipped that conversation. They wrote code first, tests second, and specs never. It worked well enough when humans reviewed every line.
It doesn't work when nobody reviews the code. It doesn't work when the builder is an AI agent that will find the shortest path to a green test suite, including paths you never considered. It doesn't work when the volume of generated code exceeds your team's reading capacity by an order of magnitude.
If you're two founders in a garage validating an idea, write code first. That's fine. But the moment you hand the keyboard to an agent and ask it to build features at scale, you need a spec — because without it, the agent will do exactly what you asked for, and nothing you actually wanted.
I shipped hallucinated content once. Once. Then I built the pipeline to prevent it. Behavioral contracts, spec adversary, structural isolation — none of these are revolutionary ideas. Dan North had the core insight in the early 2000s. StrongDM rediscovered it at scale. GitHub built tooling around it. Amazon, NIST, and the EU are codifying it into standards and law.
The only thing that changed is the stakes. When humans write code, a missing spec means a bug. When agents write code, a missing spec means return true — technically correct, functionally useless, and shipped with confidence.
Write the spec first. It was always the right thing to do. Now it's the only thing.
Sources
- Dan North, "Introducing BDD," Better Software Magazine, March 2006
- Cucumber.io, "History of BDD"
- Agile Alliance, "What is BDD?"
- Semaphore, "TDD vs. BDD: What's the Difference?" December 2024
- 303 Software, "BDD & Cucumber Reality Check 2025" September 2025
- IT Pro, "Sundar Pichai says more than 25% of Google's code is now generated by AI" November 2024
- Dan Shapiro, "The Five Levels: From Spicy Autocomplete to the Dark Factory" January 2026
- StrongDM, Software Factory
- Infralovers, "Dark Factory Architecture" February 2026
- Signals/Aktagon, "Dark Factory Architecture: How Level 4 Actually Works" March 2026
- arxiv, "Detecting Proxy Gaming in RL and LLM Alignment via Evaluator Stress Tests" 2025
- Stanford Law CodeX, "Built by Agents, Tested by Agents, Trusted by Whom?" February 2026
- GitHub Blog, "Spec-driven development with AI" September 2025
- GitHub, spec-kit repository
- AWS Blog, "Evaluating AI agents: Real-world lessons from building agentic systems at Amazon" February 2026
- Momentic, "How AI Breathes New Life Into BDD" August 2025
- CodeRabbit, "2025 was the year of AI speed. 2026 will be the year of AI quality" 2026
- Latent.Space, "How to Kill the Code Review" March 2026
- EU AI Act, Article 9: Risk Management System
- EU AI Act, High-Level Summary
- NIST, "Announcing the AI Agent Standards Initiative" February 2026
- NIST CAISI, AI Agent Standards Initiative
- Pillsbury Law, "NIST AI Agent Standards" 2026
More from “Orchemist Launch Series”
I Published AI Content Without Challenging It. Then I Built a System That Won't Let Me Do It Again.
I knew about AI hallucinations. I just didn't challenge my own output. The trust problem nobody in AI is solving — and why more agents just means more chaos. Part 1 of the Orchemist Launch Series.
Orchemist Doesn't Just Write Code — It's a Trust Factory for Anything AI Touches
A universal pipeline engine that works for code, content, slides, research, and anything else where 'good enough' isn't good enough. Part 2 of the Orchemist Launch Series.
Getting Orchemist Running in 10 Minutes — And Why You'll Talk to It Instead of Typing Commands
CLI for builders. Chatbot for operators. Both for people who've been burned by 'it works on my machine.' Part 4 of the Orchemist Launch Series.
From Factory to Dark Factory: The Orchemist Roadmap (And Why V1 Will Build V2)
Five levels of autonomy, a Go rewrite generated by its own predecessor, and the goal of making yourself unnecessary. Part 5 of the Orchemist Launch Series.