I Published AI Content Without Challenging It. Then I Built a System That Won't Let Me Do It Again.
By Conny Lazo
Agentic Engineer. Project Manager. Shipping software with AI agents.
The demo worked perfectly. It always does.
Three agents, one prompt, a slick pipeline that turned a question into a polished answer in under ten seconds. I showed it to people. They were impressed. I was impressed. Then I put it into production, and somewhere between "this is amazing" and "this is live," something broke. Not dramatically — not a crash, not an error message. Something quieter. Something worse. The output looked right. It read well. It was confident, articulate, and wrong.
That's the story of AI agents in 2026. Not the story anyone tells at conferences. The real one.
1. The Demo That Works and the Production That Doesn't
Here's a number that should make you uncomfortable: the best frontier AI agents, tested on real professional tasks — banking, consulting, law — achieve a 24% success rate on first attempt. That's the APEX-Agents benchmark from Mercor, published in January 2026, covering the most capable models money can buy on tasks at the hard end of the professional spectrum (APEX-Agents Benchmark, Mercor, January 2026). Twenty-four percent. The good news: they're very confident about the other seventy-six percent.
This isn't a niche finding. Gartner predicts that over 40% of agentic AI projects will be canceled or fail to reach production by the end of 2027 (Gartner, June 2025). Meanwhile, Gartner also reports a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025 (Gartner, December 2025). Read that again. Interest up 1,445%. Failure rate holding steady at 40%+. Everyone wants to build multi-agent systems. Almost nobody is shipping them successfully.
McKinsey arrives at the same place: 88% of organizations say they use AI, but only 6% qualify as "high performers" — capturing more than 5% of EBIT attributable to AI (McKinsey, "AI at Work but Not at Scale," 2025). A 14:1 ratio of "we use AI" to "AI is actually working for us." Most teams are building demos. Demos work. Demos always work.
The gap between demo and production is where AI projects go to die. Andrej Karpathy framed it well: we have a powerful new kernel — the LLM — but no operating system to run it properly (Karpathy, X/Twitter, October 2023). We've been arguing about which engine is best while nobody built a car that can stay on the road.
I've been a day-one ChatGPT user. I've spent three years working up the AI stack, from single prompts to chains to multi-agent pipelines. I use both Claude and GPT daily — I'm not a one-tool zealot. And I can tell you from lived experience: the problem stopped being "can AI do this?" about two years ago. The problem is now "can I trust what AI did?" Those are fundamentally different questions, and almost nobody is solving the second one.
Forty percent of enterprise apps will feature task-specific AI agents by 2026, up from less than 5% in 2025 (Gartner, August 2025). That's not a forecast — that's a tidal wave. And most of those agents will ship without quality gates, without scoring, without anyone checking whether the output is true before it goes out the door.
That should terrify you. It terrifies me. Because I've been there.
2. The More Agents, Worse Results Pattern
Here's the thing nobody wants to hear: adding more agents to your system often makes it worse, not better. People who haven't run multi-agent systems in production say "but specialization improves quality." People who have run them nod quietly.
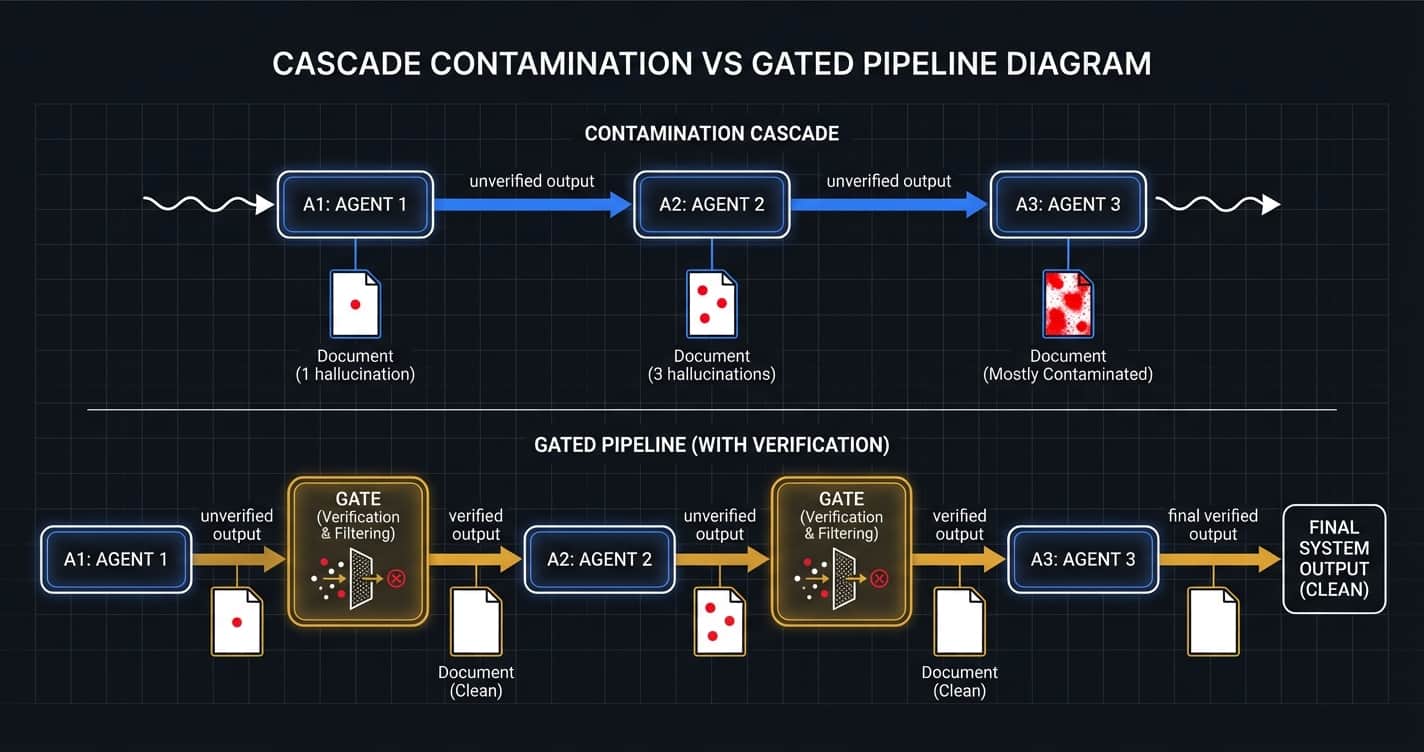
The mechanism is called cascade contamination, and Galileo.ai documented it well: failures in one agent silently corrupt the state of others, leading to subtle hallucinations rather than obvious failures (Galileo.ai, July 2025). That word — silently — is doing all the work in that sentence. The system doesn't crash. It doesn't throw an error. It just starts being wrong in ways that look right.
Individual agents may function perfectly in isolation. The hallucinations emerge from their collective interaction. A peer-reviewed survey on LLM-based agent hallucinations found that in multi-agent systems, information asymmetry between agents causes "vague or incomplete instructions that hinder task comprehension and amplify the risk of biased decisions." Agents generate redundant content that "obscures critical signals" (arXiv:2509.18970, September 2025).
Here's how I think about it. Picture a kitchen with five cooks. Normally, that's fine — one does sauces, one does proteins, they taste as they go, they course-correct. Now picture five cooks who can't taste the food. They've never tasted food. They're cooking based on what the previous cook put in the pot. The last cook added salt, so this cook adds salt. And the next cook adds salt, because the last two cooks added salt. Nobody checks if the soup is edible. They just keep passing the pot.
That's a multi-agent pipeline without quality gates. Mistakes made early become the inputs to subsequent decisions, amplifying the original error rather than containing it (humai.blog, March 2026). The agents aren't stupid. They're diligent. They're confidently building on top of garbage because nobody told them the foundation was garbage.
I run multi-agent pipelines daily. Sonnet builds, Opus reviews, Haiku scores. But the key isn't which models I use — it's that the same model never judges its own work. A builder can't grade its own exam. The moment you let an agent evaluate its own output, you've built a system that validates its own mistakes.
This is also why "agent sprawl" is becoming a real problem. CIO.com called 2026 "the year of the collision" for autonomous agents (CIO.com, February 2026). Forgotten autonomous processes — "ghost agents" — continue to ping APIs and burn tokens without providing value. Two autonomous systems can get stuck in recursive communication loops, racking up thousands in API costs over a weekend (Company of Agents, January 2026). More agents, more surface area, more ways to fail quietly.
The answer isn't fewer agents. The answer is accountability between agents.
3. The Scaffolding Tax
Every team building AI pipelines independently discovers the same list of things they need:
- Retry logic with exponential backoff
- Model fallback chains
- Output parsing and validation
- Quality gates (often skipped "just this once")
- Human-in-the-loop review queues
- Context management and state across sessions
- Error recovery, observability, logging
Every team. Every time. From scratch. Always with the promise of "we'll clean this up later." Later never comes.
Vercel documented this beautifully. They built a sophisticated internal text-to-SQL agent with specialized tools, heavy prompt engineering, and careful context management. It worked — kind of. But it was fragile, slow, and required constant maintenance. In their own words: "We were spending more time maintaining the scaffolding than improving the agent" (Vercel Engineering Blog, December 2025).
Their solution? They removed 80% of their agent's tools. Went from 15+ specialized tools down to 2. Gave the agent direct bash access instead. Result: 100% success rate versus the previous 80%. Fewer tokens, 3.5x faster. They solved the scaffolding problem by deleting the scaffolding. Try pitching that to an engineering team that just spent three months building it.
By one industry estimate — five senior engineers, three months, custom connectors for a pilot that gets shelved — you're looking at $500k+ in salary burn before a line of product ships (Composio.dev, December 2025). Half a million on plumbing instead of product. Per team, per attempt.
When I built Orchemist, Sprint 1 was exactly this work: auto-retry, model fallback, security gates, spec validation. Six issues, average quality score of 0.990. The scaffolding tax isn't optional — someone has to pay it. The question is whether every team pays it independently or whether someone builds the infrastructure once.
4. Why the Existing Tools Don't Solve This
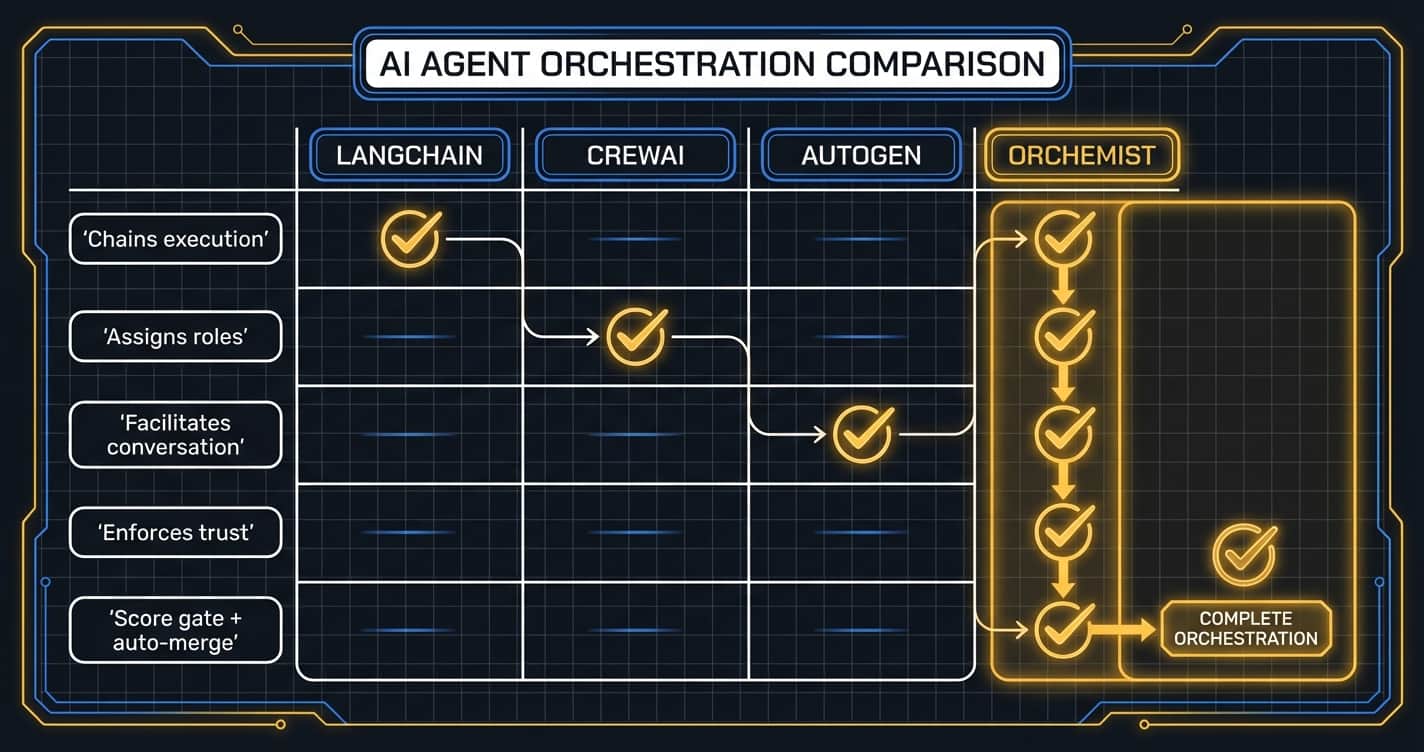
Let me be clear: LangChain, CrewAI, and AutoGen are not bad tools. They solve real problems. They're just solving different problems than the one I'm talking about.
LangChain excels at rapid prototyping, RAG pipelines, and connecting LLMs to tools. Its ecosystem is vast. LangGraph — LangChain's newer graph-based offering — does support conditional routing, which gets closer to gate-like patterns. But as the original LangChain grew, so did the criticism: too complex, too abstract, not production-ready (neurlcreators.substack, June 2025). And the fundamental issue isn't complexity — it's architecture. Even with conditional edges, a chain connects steps. A rail scores output and blocks the next step from seeing garbage. A chain says "do A, then B, then C." A rail says "do A, check A against a rubric, score it, and if A fails, stop — B doesn't get to see bad output from A."
CrewAI has an elegant model: define agents by role — Researcher, Writer, Editor — and let them collaborate. Quick setup, clean API, good for small-to-mid-scale projects (o-mega.ai, 2026). But roles are not accountability. A "Researcher" agent can hallucinate facts, and the role provides no check on output quality. Having a "fact-checker" role is not the same as having a fact-checking gate that blocks the pipeline if the score fails. Roles are job titles. Gates are checkpoints. Job titles don't stop trains.
AutoGen enables structured multi-agent conversations — flexible, powerful for research tasks that benefit from dialogue between models. DSPy and Instructor add their own forms of validation — assertions, Pydantic schemas. These are genuine steps in the right direction. But orchestrating a conversation with validation is different from orchestrating a pipeline with scoring and hard gates. Pydantic tells you the output is the right shape. It doesn't tell you whether it's true.
Here's the gap I haven't seen filled: built-in scoring gates that evaluate output quality against a rubric and block pipeline progression on failure. Not "is this valid JSON?" But: "Did this agent actually do what it was supposed to do, and is the output good enough to send downstream?" Answered by a scoring agent running a rubric. With a threshold. That's a hard stop, not a retry.
That's not a criticism of these tools. That's a different design goal. They assume agents produce good output and focus on workflow efficiency. I assume agents sometimes produce bad output and focus on catching it before it ships.
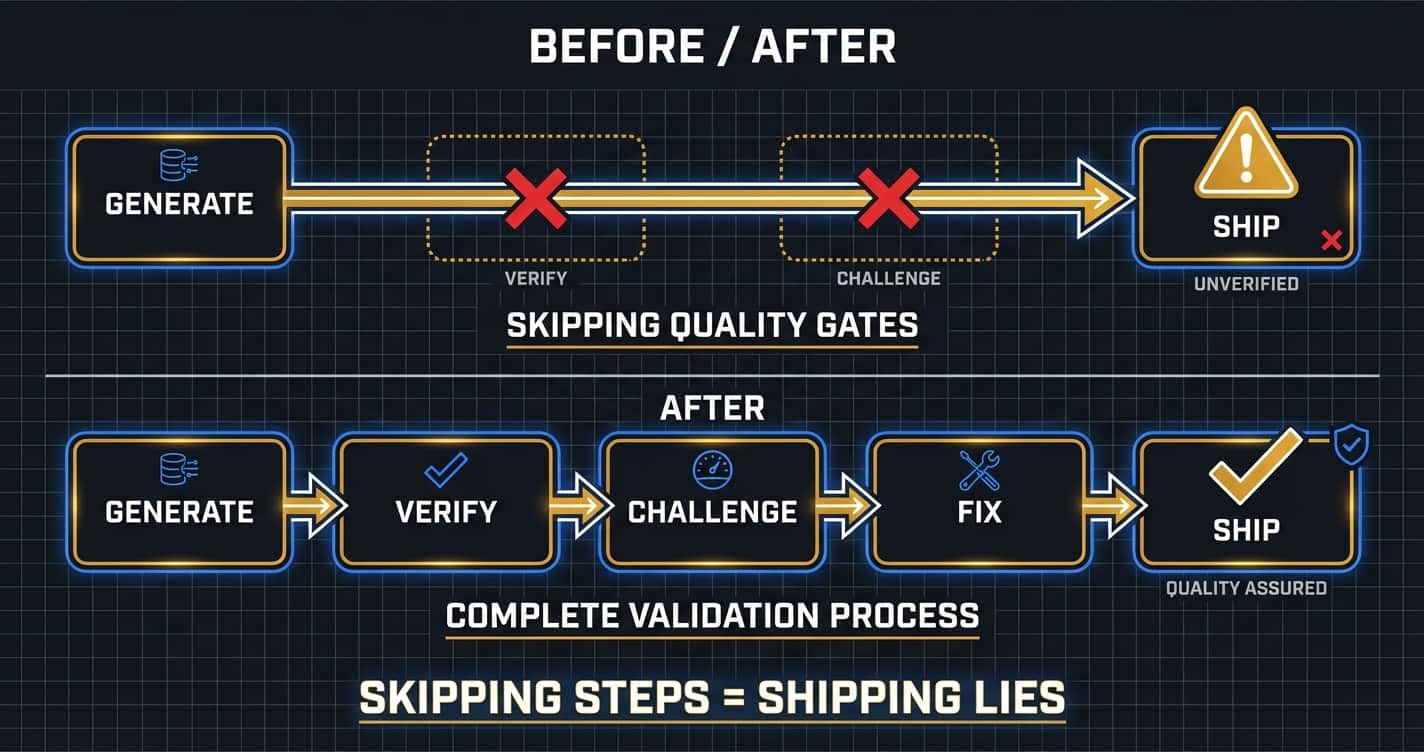
My rule is simple and non-negotiable: the score gate is THE LAW. No bypass, ever. Not "just this once." Not "we're in a hurry." Not "this one looks fine." The moment you bypass quality gates "just this once," you've lost the system. You haven't made an exception — you've established the new baseline.
5. The Day I Shipped Something That Wasn't True
I need to tell you about the time I broke my own rule.
I was running a content pipeline — AI-generated research, synthesis, and publishing. The system worked. I'd used it multiple times. I was comfortable with it. Comfortable enough to skip the fact-checking step. Not consciously, not as a deliberate choice. I was excited. The output looked good. I trusted the machine.
I shipped hallucinated content through a pipeline that skipped fact-checking, and I published it on LinkedIn under my name. Conny Lazo, writing confidently about something that wasn't true.
The backlash was earned. The credibility I'd built — the articles on AI orchestration, the pieces on the "more agents, worse results" pattern, the technical reputation — took a hit. Not because people were cruel. Because they were right. I'd published something false and put my name on it. That's not a system failure. That's a judgment failure. My judgment.
I sat with it. I wanted to blame the AI. I wanted to blame the tool, the model, the pipeline. But the pipeline didn't skip fact-checking — I skipped fact-checking. The AI didn't publish the post — I published the post. The system I was proud of became the system that embarrassed me, and the only variable that changed was my own discipline.
This is the part of the story that earns me the right to have opinions about everything else in this article. I'm not theorizing about what happens when quality gates fail. I shipped a lie. It had my name on it. And I had to decide what to do about it.
What I did was build a system that wouldn't let me do it again.
I didn't need a better agent. I needed a better process.
6. The Insight
The insight that became Orchemist is simple enough to fit in one sentence: orchestration isn't intelligence — it's accountability.
The AI agents we have today are powerful enough. The APEX benchmark shows a 24% pass rate on first attempt for complex professional tasks — that's low, but it's not zero. The agents aren't failing because they're dumb. They're failing because nobody is checking their work. Nobody is scoring the output against a rubric. Nobody is blocking bad results from flowing downstream. Nobody is enforcing the difference between "this looks right" and "this is right."
I built Orchemist in about three and a half weeks. Four sprints, 42+ issues, 4,698+ tests, an average quality score of 0.993 across every piece of code that shipped. Sonnet builds. Opus reviews. Haiku scores — and because scoring is automated, the gates hold at 1,000 runs a day just as well as they hold at one. The same model never judges its own work. The score gate is THE LAW — no bypass, ever.
The 0.993 average only means something if the rubric means something. I know this because the system caught its own calibration error: a scoring bug in issue #383 that was silently undervaluing certain output types. The pipeline flagged it, failed the gate, and surfaced the problem before it could contaminate the rest. The system that enforces quality caught a flaw in quality enforcement itself. That's not a coincidence. That's the architecture working.
The factory builds the factory.
That's not a metaphor. The orchestration engine was built by the orchestration engine. Every component went through the same pipeline: specification, implementation, review by a different model, scoring against a rubric, and a hard gate that blocks anything below threshold. The system that enforces quality was itself built under that enforcement. If the system's own code can't pass its own gates, the system has no business judging anyone else's code.
I didn't build Orchemist because I wanted an orchestration engine. I built it because I shipped something that wasn't true, and I needed a system that wouldn't let me do that again.
Intelligence without accountability is just confident wrongness. And I'd had enough of confident wrongness.
This is Part 1. In the next article, I'll show you what I actually built — the architecture, the pipeline, the score gates. Not the philosophy. The machinery.
Sources
-
APEX-Agents Benchmark (Mercor, January 2026). "APEX-Agents: Benchmarking AI Agents on Real Professional Tasks." arXiv:2601.14242. APEX-Agents: Benchmarking AI Agents on Real Professional Tasks.
-
TechCrunch (January 22, 2026). "Are AI Agents Ready for the Workplace? A New Benchmark Raises Doubts." Are AI Agents Ready for the Workplace? A New Benchmark Raises Doubts.
-
Gartner (June 25, 2025). "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027.
-
Gartner (August 26, 2025). "40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026." 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026.
-
Gartner (December 18, 2025). "Multiagent Systems in Enterprise AI." Multiagent Systems in Enterprise AI.
-
McKinsey (2025). "AI at Work but Not at Scale." AI at Work but Not at Scale.
-
Andrej Karpathy (October 2023). LLM as OS kernel. X/Twitter. Andrej Karpathy
-
Galileo.ai (July 11, 2025). "Multi-Agent AI Gone Wrong: How Coordination Failure Creates Hallucinations." Multi-Agent AI Gone Wrong: How Coordination Failure Creates Hallucinations.
-
arXiv:2509.18970 (September 23, 2025). "LLM-based Agents Suffer from Hallucinations: A Survey." LLM-based Agents Suffer from Hallucinations: A Survey.
-
humai.blog (March 2026). "Why Your AI Agent Works in the Demo and Breaks in the Real World." Why Your AI Agent Works in the Demo and Breaks in the Real World.
-
CIO.com (February 2026). "Taming Agent Sprawl: 3 Pillars of AI Orchestration." Taming Agent Sprawl: 3 Pillars of AI Orchestration.
-
Company of Agents (January 12, 2026). "AI Agent ROI in 2026: Avoiding the 40% Project Failure Rate." AI Agent ROI in 2026: Avoiding the 40% Project Failure Rate.
-
Vercel Engineering Blog (December 22, 2025). "We Removed 80% of Our Agent's Tools." We Removed 80% of Our Agent's Tools.
-
Composio.dev (December 2025). "The 2025 AI Agent Report: Why AI Pilots Fail in Production." The 2025 AI Agent Report: Why AI Pilots Fail in Production.
-
dev.to (February 2026). "The Agent Harness Is the Architecture." The Agent Harness Is the Architecture.
-
neurlcreators.substack (June 17, 2025). "Is LangChain Still Worth Using in 2025?" Is LangChain Still Worth Using in 2025?
-
o-mega.ai (2026). "LangGraph vs CrewAI vs AutoGen: Top 10 AI Agent Frameworks." LangGraph vs CrewAI vs AutoGen: Top 10 AI Agent Frameworks.
-
The Orchemist Chronicles — LOGBOOK.md (Conny Lazo & Toscan, March 2026). Primary source.
More from “Orchemist Launch Series”
Orchemist Doesn't Just Write Code — It's a Trust Factory for Anything AI Touches
A universal pipeline engine that works for code, content, slides, research, and anything else where 'good enough' isn't good enough. Part 2 of the Orchemist Launch Series.
When AI Writes the Code, Who Checks the Homework? Behavior-Driven Development for the Agent Era
BDD sat on the shelf for twenty years. Then AI started writing production code, and we realized: if no human wrote it, the only thing between you and shipping 'return true' to production is a behavioral spec. Part 3 of the Orchemist Launch Series.
Getting Orchemist Running in 10 Minutes — And Why You'll Talk to It Instead of Typing Commands
CLI for builders. Chatbot for operators. Both for people who've been burned by 'it works on my machine.' Part 4 of the Orchemist Launch Series.
From Factory to Dark Factory: The Orchemist Roadmap (And Why V1 Will Build V2)
Five levels of autonomy, a Go rewrite generated by its own predecessor, and the goal of making yourself unnecessary. Part 5 of the Orchemist Launch Series.