Orchemist Doesn't Just Write Code — It's a Trust Factory for Anything AI Touches
By Conny Lazo
Builder of AI orchestras. Project Manager. Shipping things with agents.
The Pattern Nobody Told You About

Here's something that took me an embarrassing number of failures to figure out: shipping code backed by 6,621 tests and fact-checking a 3,000-word article are structurally the same problem.
Not similar. Not "kinda related if you squint." The same problem — wearing different clothes.
I built Orchemist from scratch in six weeks. It has shipped 640+ issues across 10 sprints with near-zero manual code. And somewhere around sprint 3, staring at a pipeline diagram at 2 AM in Vienna, I realized the trust pattern I'd built for code review was identical — phase by phase, gate by gate — to the one I needed for content, slide decks, and research.
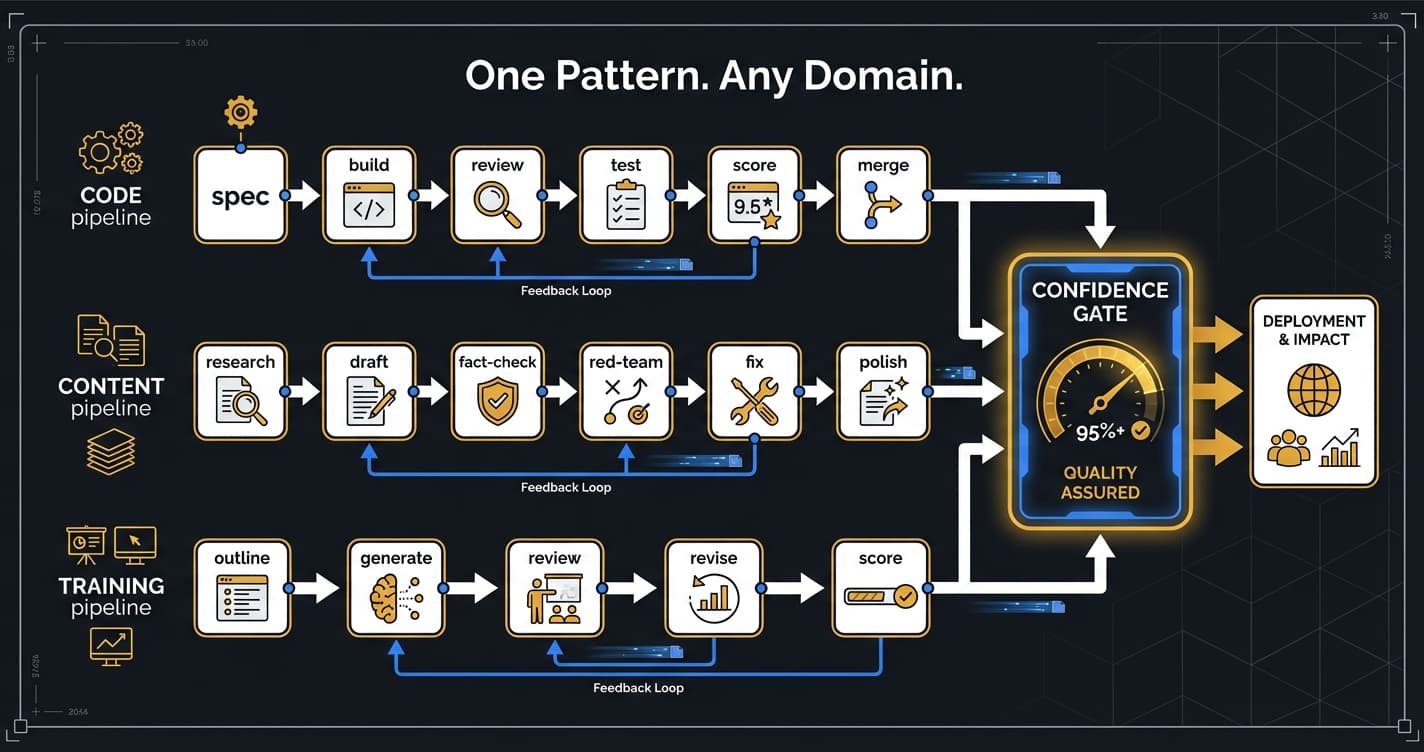
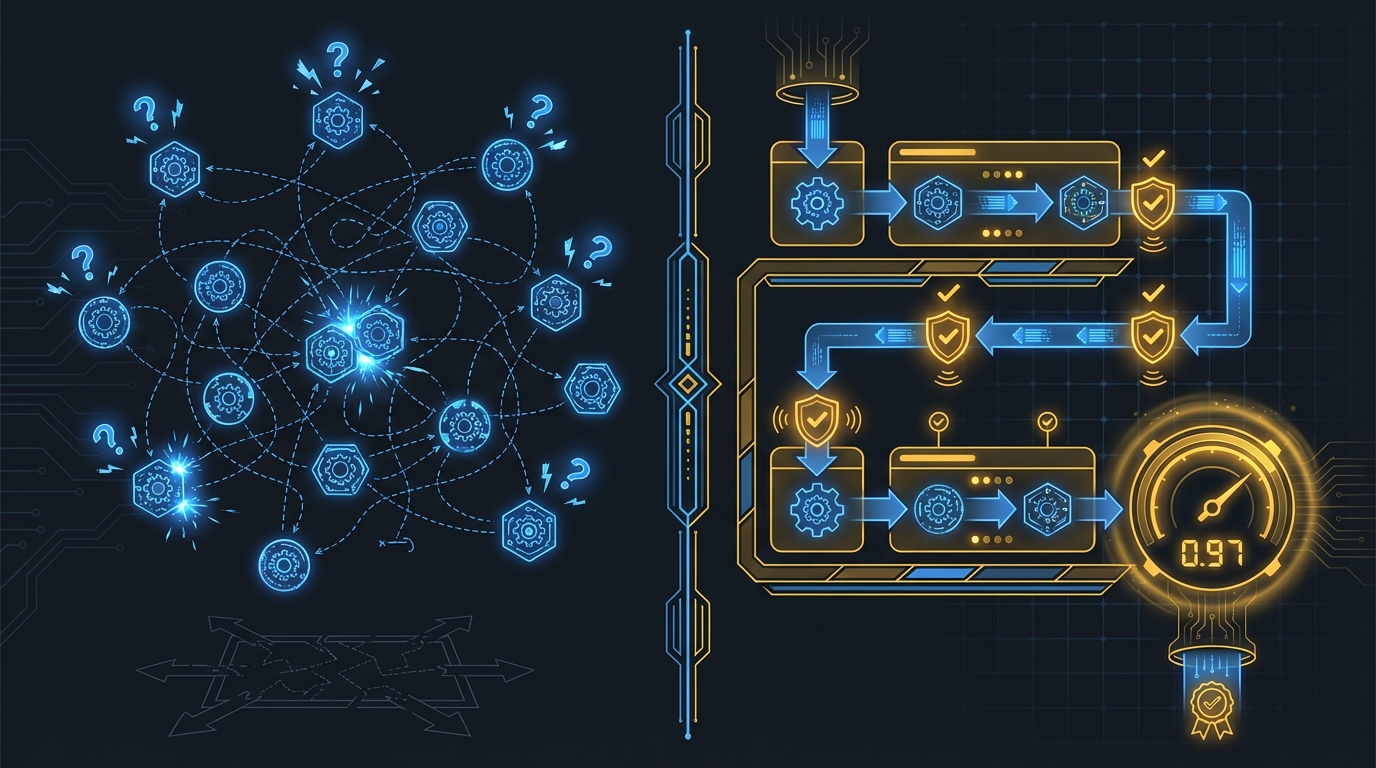
The pattern has seven phases: Research, Create, Verify, Challenge, Fix, Validate, Score. It doesn't matter if the output is Python or PowerPoint. The pipeline doesn't know. It just knows there are seven stops on the railroad, and it stops at every one.
This shouldn't be surprising, but it is. Most people think trust is domain-specific. You trust code differently than you trust prose. But the mechanism of trust — the structural process that turns "I hope this is right" into "I can prove this is right" — is domain-agnostic. We've known this for centuries. Financial audits, legal review, peer-reviewed science — all inspired by the same instinct: don't let the person who wrote the thing be the only person who checks it. AI just makes it tempting to skip those steps because the output looks confident.
And confident-looking output is the most dangerous kind. The best frontier AI agents achieved a 24% pass rate on real professional tasks in one major benchmark (APEX-Agents Benchmark, Mercor, January 2026). They failed 76% of the time. They were very confident about it.
That confidence gap maps onto a larger adoption one. McKinsey found that while most organizations are experimenting with AI, very few have scaled it meaningfully (McKinsey, 2025). Gartner predicts over 40% of agentic AI projects will be canceled or fail to reach production by 2027 (Gartner, June 2025). Organizations can deploy AI everywhere and still fail to capture value if they can't verify what the AI produced. That gap is where Orchemist lives.
If you read Article 1 in this series, you know how I got here — I shipped something false, lost credibility, and decided that was the last time. This article is about what I built instead: a trust pattern that has proven itself across code, content, and presentation pipelines — and that I believe generalizes further.
Software Development — The Proving Ground

Let me give you the scoreboard first, then tell you why the scoreboard matters.
Ten sprints. 640+ issues filed. 185+ pull requests merged. 6,621 tests. Average score on recent sprints: 0.95+; overall across 388 pipeline runs: 0.88 — where the rubric measures code correctness, test coverage, and behavioral compliance against acceptance criteria. Manual code written by a human: approximately zero — a handful of developer-experience fixes, the kind of thing where you adjust a font size because life's too short to make a pipeline run for that (LOGBOOK.md, "The Numbers").
Those numbers sound impressive. They should. But numbers are easy to cherry-pick and easier to misunderstand. The 0.88 overall includes rubric calibration failures and pipeline-run anomalies mid-development — most notably incident #383, where a misconfigured grader returned 0.400 on builds that were actually fine. What actually matters is the three times the system caught something a human would have missed — and the one time it graded itself wrong.
Incident #393: The Robot Rewired the Wrong Circuit
Sprint 3. A builder agent — Sonnet, the fast one, the enthusiastic one — modified the main branch's working tree instead of its feature branch. Broke the CLI for five minutes. The root cause was embarrassingly simple: no git checkout in the implement phase template (LOGBOOK.md, Chapter 5).
The fix was a template update. One line. But here's the thing: the factory diagnosed its own process failure. It didn't just find a code bug. It found a workflow bug. The Verify phase caught what would have been a corrupted main branch. This is why you don't skip stations on the railroad.
Incident #396: The System That Approved Negative Money
Opus — the reviewer, never the builder on its own work — caught a genuine bug in the budget guard logic. The code would have passed negative remaining budgets. Which is to say, it would have happily told you that you have more money than you have. Opus read someone else's code with fresh eyes and said: no (LOGBOOK.md, Chapter 5).
"This is exactly why the loop exists" (LOGBOOK.md, Chapter 5).
The builder fixed it. The re-review confirmed the fix. The whole cycle took minutes. Without the independent Challenge phase — a different model reviewing the work with no loyalty to the original implementation — this bug ships. It ships quietly, it ships confidently, and three weeks later someone discovers their budget numbers are wrong and nobody knows why.
Incident #414: The Ghost in the CLI
This one is my favorite because it's the sneakiest. Opus caught a missing @main.command() decorator in issue #414 that would have silently dropped the orch workers command from the CLI (LOGBOOK.md, Chapter 6).
The command didn't crash. It didn't throw an error. It just... vanished. You'd type orch workers and nothing would happen. No feedback. Like a ghost. The Validate phase — the post-fix re-check — saw the ghost.
Silent failures are the worst kind. They don't announce themselves. They just sit there, quietly making your system worse, until a user reports that something "used to work." The review loop exists precisely for this.
Bonus: The Grader Who Failed Its Own Exam
Issue #383. The pipeline scored 0.400 on legitimate builds. Panic stations. Except the builds were fine. The rubric expected raw code output, but the pipeline was outputting summaries. The grader was looking for the wrong thing (LOGBOOK.md, Chapter 4).
We fixed the rubric, not the pipeline. Know what you're measuring. This is advice that predates AI by several thousand years.
Sprint by sprint, the progression is hard to argue with: early sprints shipped 6–12 issues at 0.990+ average; later sprints are posting 0.970–1.000 on individual issues with 443+ new tests added mid-sprint. These aren't edge cases. These are the expected failure modes of excited engineers — human or artificial — moving fast. The system doesn't prevent failures. It catches them before they ship.
Written Content — Where the Scar Tissue Comes From
I've already told the story of how I shipped something false and what that cost me — that's Article 1 in this series. I'm not going to retell it. What I will tell you is what I built afterward.
The content pipeline runs the same seven phases as the coding pipeline: Research → Create → Verify → Challenge → Fix → Validate → Score. Same railroad. Different cargo. The pipeline doesn't care if it's reviewing Python or prose. It just stops at every station (LOGBOOK.md, pipeline templates).
Three architectural decisions make this work:
Writer ≠ Reviewer. The agent that writes the draft cannot fact-check the draft. Same principle as code: Sonnet builds, Opus reviews, and never the same model judging its own work. This seems obvious. It wasn't obvious. We learned it the same way you learn not to touch a hot stove (LOGBOOK.md, Chapter 1).
Adversarial Red-Team. The Challenge phase doesn't just check facts. It actively argues against the content. It looks for what's missing, what's misleading, what could embarrass you at 3 AM when someone on the internet decides to fact-check your article with more enthusiasm than you brought to writing it. This is not paranoia. This is architecture.
The research on why this matters is grim. In multi-agent systems, information asymmetry between agents causes "vague or incomplete instructions that hinder task comprehension and amplify the risk of biased decisions" (arXiv:2509.18970, September 2025). The red-team phase exists to flip that asymmetry — creating an agent whose entire job is to find problems, with no incentive to agree with the draft.
Humor Calibration. There is a pipeline phase whose sole purpose is to ask: "Is this actually funny?" It exists because dry wit and just dry are hard to tell apart from the inside. The voice check phase reads the draft and asks whether the sardonic energy is working or whether it sounds like a corporate blog trying too hard. This is the kind of quality gate that sounds ridiculous until you ship an article that's accidentally condescending and lose half your audience in the first paragraph.
The score gate applies to content the same way it applies to code. If the article doesn't score above threshold, it doesn't publish. No exceptions. No "well, the deadline is tomorrow." The deadline can wait. Your credibility can't.
More agents don't automatically mean better results — in fact, the opposite. Individual agents may function perfectly in isolation, but hallucinations emerge from their collective interaction as interaction pathways multiply exponentially (Galileo.ai, July 2025). The content pipeline succeeds not because it uses many agents, but because each agent has a specific adversarial role with hard gates between them.
Slides, Research, and the Frontier

Here's where I need to be honest about what's proven and what's still being built. The credibility of everything I've told you so far depends on me being accurate about the boundary.
Proven: The Cybersecurity Training Deck
55 slides. Embedded quizzes. Built for an internal security awareness program through Orchemist's presentation pipeline. Same seven phases: research the topic, create the slides, verify accuracy, challenge the content with quiz generation, fix issues, validate the whole deck, score it (LOGBOOK.md).
The quiz generation is the interesting part. It serves as both a learning tool and a verification mechanism. If the pipeline can't generate a coherent quiz question from a slide, that slide probably doesn't say anything clear enough to teach. The Challenge phase doubles as quality assurance for educational content. The pipeline doesn't know it's doing two things at once. It just knows there's a station to stop at.
Proven: Structured Research with Citations
The research pipeline — the one that produced the research brief for this very article — follows the same pattern. Research → synthesize → verify citations → challenge claims → fix gaps → validate coherence → score. Every factual claim gets a source. Every source gets a credibility rating. The pipeline that fact-checks articles is itself fact-checked by the same pattern.
This is either very reassuring or extremely recursive. Possibly both. For what it's worth, a human still reads the output before anything publishes — the pipeline builds the case, the human makes the call.
Proven: The Content Pipeline in Production
You're reading its output right now. This article — Article 2 of 4 in the Orchemist Launch Series — was written, fact-checked, red-teamed, and scored by the content pipeline. Articles 1 through 4 are the live production test. The factory builds the factory (LOGBOOK.md, recurring theme).
Trust Calibration: Still Being Earned
The composite confidence score sits at 0.88 overall across 388 pipeline runs. A handful of auto-merges. Mostly human review. That's not a failure — it's the engine being honest about where it stands.
The work going through the pipeline right now is genuinely hard: new executors, daemon re-fetch logic, adversary self-healing. The kind of work where a miss costs days. A routing engine that defers to human review on challenging work isn't broken. It's calibrated correctly.
The scores are trending up. Two of the last three runs scored 1.0. A few issues have auto-merged cleanly. The trust is being built the only way trust can be built — through repeated hard work, verified outcomes, and time. The sweat needs to seep through.
Planned: The V2 Rewrite and Creative Pipelines
The V1 coding pipeline will generate the V2 Go rewrite of the engine itself. Video pipelines, social content pipelines, long-form research pipelines — these are designed, templated, and waiting for production testing. I'm not going to tell you they work until they've worked. What I can tell you is that the template structure is the same seven phases. Every time.
The pattern here isn't complexity — it's the opposite. Vercel learned a similar lesson building their text-to-SQL agent: they removed 80% of their tools and went from 80% success to 100%, 3.5x faster. "We were spending more time maintaining the scaffolding than improving the agent" (Vercel Engineering Blog, December 2025). Whether you're building SQL agents or trust pipelines, the answer turns out to be the same: fewer moving parts, harder gates.
The honest trade-off: Seven phases for everything costs time and tokens. A simple blog post doesn't need the same scrutiny as production code. Orchemist currently applies the full pipeline uniformly — trust calibration in Sprint 4 is partly about learning when to shorten the track. The railroad metaphor has a limitation: real railroads have express routes that skip stations. Orchemist doesn't, yet.
The Universal Pattern — Seven Phases of Trust
Research → Create → Verify → Challenge → Fix → Validate → Score.
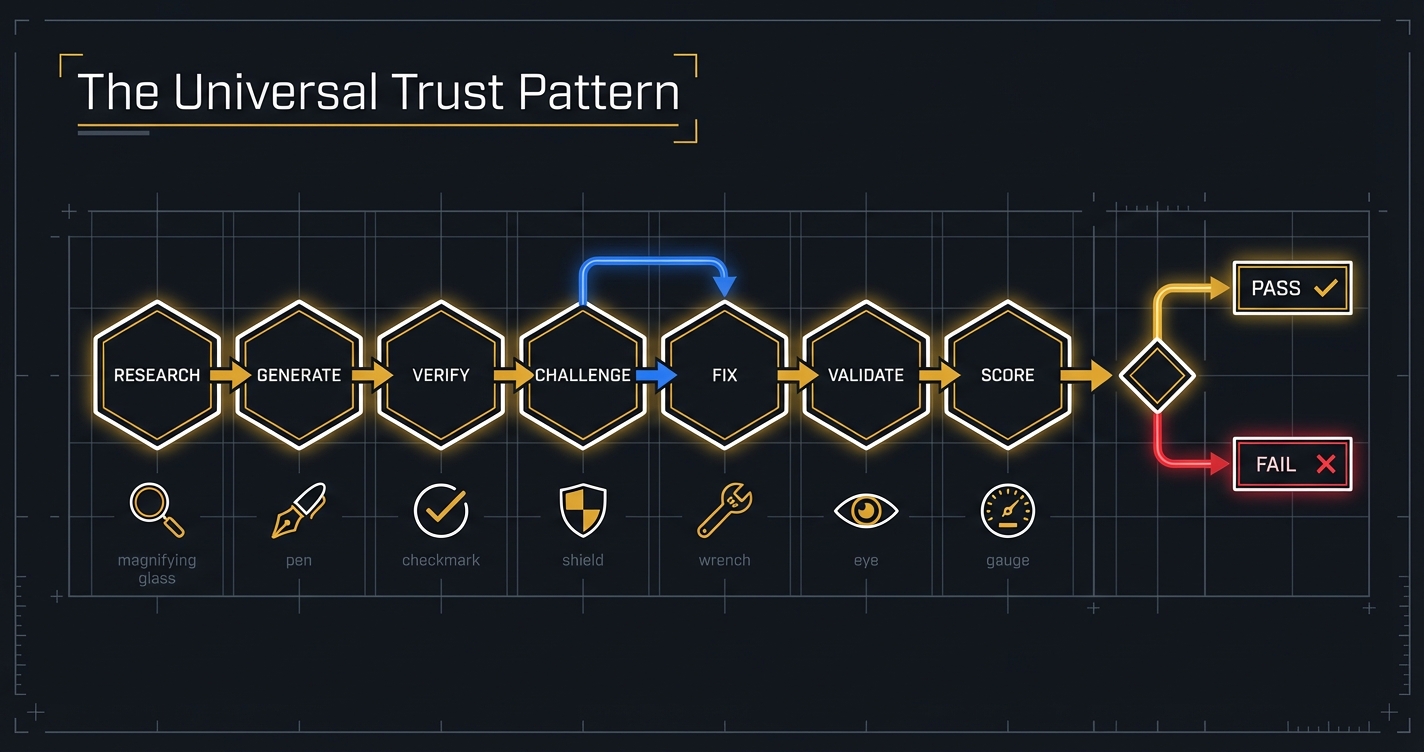
"Phases flow like a railroad — no shortcuts" (LOGBOOK.md, Chapter 1).
Trains don't take shortcuts. They stop at every station. Not because the conductor is cautious, but because the track is laid that way. The track is laid that way because someone, at some point, tried to skip a station, and something caught fire.
Each station in Orchemist's trust railroad exists because of a specific failure:
Research exists because building without understanding the problem wastes everyone's time. Sprint 1 taught this.
Create is where the work happens. Sonnet builds. It's fast. It's capable. It's occasionally overeager. Which is why Create is not the last stop.
Verify exists because I shipped false information. The LinkedIn incident from Article 1. You skip the fact-check, you ship the lie. Verify is the scar tissue.
Challenge exists because Opus caught the negative budget bug in #396. An independent reviewer with no loyalty to the original implementation. The agent that writes the code does not get to declare the code correct. Nobody grades their own exam.
This is also where Orchemist differs from a standard CI/CD pipeline. CI/CD runs deterministic tests against known acceptance criteria. The Challenge phase runs an adversarial model against the work — the goal isn't to confirm it passes tests, it's to find the tests that were never written. One checks the map. The other checks whether you're in the right country.
Fix requires human-readable diagnostics, not just error codes. The DiagnosisEngine built in Sprint 3 doesn't just say "test failed." It says why, proposes a fix, and tracks whether the fix introduced new problems (LOGBOOK.md, Chapter 5).
Validate exists because #414 would have shipped a silent feature regression. The command vanished without a trace. Post-fix validation caught the ghost. You don't get to skip this because the fix "looks right."
Score is the gate. Not a suggestion. Not a metric you can override when you're in a hurry. The score gate is THE LAW (LOGBOOK.md, recurring maxim). The moment you bypass it "just this once," you've lost the system.
The philosophical point here isn't about AI. It's about trust. We've always known that complex outputs need multi-step verification. We knew it for financial audits, for legal contracts, for engineering specifications. AI just makes it tempting to skip those steps because the output looks confident. AI output looks confident whether it's right or wrong.
This is not a new problem. Overconfident experts existed long before large language models. We built institutional processes — audit, peer review, quality assurance — to catch them. Orchemist is that institutional process, automated.
Other Tools Orchestrate Agents. Orchemist Orchestrates Trust.
LangChain chains execution. CrewAI assigns roles. AutoGen facilitates conversations. These are real tools solving real problems, and I'm not here to dismiss them — each has thriving communities and legitimate production use cases.
But there's a meaningful difference between having a "fact-checker" role in your agent system and having a fact-checking gate that blocks progress when the score fails. One is a responsibility. The other is a checkpoint. Responsibilities can be ignored under pressure. Gates can't.
To be fair, some of these frameworks can implement hard gates — they're flexible enough to support it. The point isn't that they can't. The point is that Orchemist makes gated trust the default architecture, not an optional add-on. The railroad is the product.
Gartner reports a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025 (Gartner, December 2025). 40% of enterprise apps will feature task-specific AI agents by 2026, up from less than 5% in 2025 (Gartner, August 2025). Everyone is building agents. The trust layer is often an afterthought.
The APEX-Agents benchmark tested frontier AI agents on real professional tasks. The best pass rate: 24%. These agents aren't failing because they're incapable. They're failing because the surrounding infrastructure doesn't verify their output (APEX-Agents Benchmark, Mercor, January 2026; TechCrunch, January 2026).
Orchemist is one approach to that verification infrastructure. It's the one I built because I needed it.
The name — part orchestrator, part alchemist — isn't just branding. "Turning raw AI capability into gold" (LOGBOOK.md, Chapter 2). But it's not transmuting lead into gold. It's transmuting competence into confidence. The AI models are competent. Claude, GPT, Gemini — they can write code, draft articles, build slide decks. What they can't do is tell you whether their output is trustworthy. That's not their job. That's the railroad's job.
Ten sprints. 640+ issues. 6,621 tests. 0.88 average score across 388 runs, climbing to 0.95+ in recent sprints. Near-zero manual code. Three code bugs caught that would have shipped silently — plus one rubric failure that would have made the grader worthless. One content pipeline that exists because I shipped a lie and decided never again.
The pattern works. Not because it's clever. Because it stops at every station.
Sources
-
LOGBOOK.md — "The Orchemist Chronicles" — Conny Lazo & Toscan, March 2026. Primary internal source for all sprint data, incidents, quotes, and pipeline architecture. [Internal document]
-
Gartner: "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027" — June 25, 2025. Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027
-
Gartner: "Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026" — August 26, 2025. Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026
-
Gartner: "Multiagent Systems in Enterprise AI" — December 18, 2025. Multiagent Systems in Enterprise AI
-
McKinsey: "AI at Work but Not at Scale" — 2025. AI at Work but Not at Scale
-
APEX-Agents Benchmark (Mercor) — January 2026. APEX-Agents Benchmark (Mercor)
-
TechCrunch: "Are AI Agents Ready for the Workplace?" — January 22, 2026. Are AI Agents Ready for the Workplace?
-
Galileo.ai: "Multi-Agent AI Gone Wrong: How Coordination Failure Creates Hallucinations" — July 11, 2025. Multi-Agent AI Gone Wrong: How Coordination Failure Creates Hallucinations
-
arXiv: "LLM-based Agents Suffer from Hallucinations: A Survey" — September 23, 2025. LLM-based Agents Suffer from Hallucinations: A Survey
-
Vercel: "We removed 80% of our agent's tools" — December 22, 2025. We removed 80% of our agent's tools
-
neurlcreators.substack: "Is LangChain Still Worth Using in 2025?" — June 17, 2025. Is LangChain Still Worth Using in 2025?
-
propelius.ai: CrewAI Comparison Analysis — February 2026. propelius.ai: CrewAI Comparison Analysis
-
o-mega.ai: "LangGraph vs CrewAI vs AutoGen: Top 10 AI Agent Frameworks" — 2026. LangGraph vs CrewAI vs AutoGen: Top 10 AI Agent Frameworks
More from “Orchemist Launch Series”
I Published AI Content Without Challenging It. Then I Built a System That Won't Let Me Do It Again.
I knew about AI hallucinations. I just didn't challenge my own output. The trust problem nobody in AI is solving — and why more agents just means more chaos. Part 1 of the Orchemist Launch Series.
When AI Writes the Code, Who Checks the Homework? Behavior-Driven Development for the Agent Era
BDD sat on the shelf for twenty years. Then AI started writing production code, and we realized: if no human wrote it, the only thing between you and shipping 'return true' to production is a behavioral spec. Part 3 of the Orchemist Launch Series.
Getting Orchemist Running in 10 Minutes — And Why You'll Talk to It Instead of Typing Commands
CLI for builders. Chatbot for operators. Both for people who've been burned by 'it works on my machine.' Part 4 of the Orchemist Launch Series.
From Factory to Dark Factory: The Orchemist Roadmap (And Why V1 Will Build V2)
Five levels of autonomy, a Go rewrite generated by its own predecessor, and the goal of making yourself unnecessary. Part 5 of the Orchemist Launch Series.