
Choosing Your Conductor: The AI Engine That Runs Your Orchestra
By Conny Lazo
Builder of AI orchestras. Project Manager. Shipping things with agents.
I ran the numbers on what my AI agent workload would cost via API calls. The answer? Over $800/month in tokens alone.
My Claude Max subscription covers the same workload for a flat monthly fee. Zero per-token anxiety. Zero cost surprises.
Reddit analysis confirms it: subscriptions can be up to 36x cheaper than API calls for heavy users. Once I saw that math, I never looked back.
The Conductor Analogy
Your main AI model isn't just a tool. It's the conductor of your digital orchestra.
A bad conductor ruins even the best musicians. A great conductor makes average musicians sound brilliant.
I learned this running my first multi-agent system. I used GPT-3.5 as the orchestrator because it was cheap. Watched it coordinate 5 agents into complete chaos. Wrong priorities, conflicting instructions, circular dependencies.
Switched to Claude Opus as the orchestrator. Same 5 agents suddenly worked in perfect harmony.
The conductor sets the tone. Choose wisely.
My 3-Tier System
I run a hierarchy that mirrors how human organizations work:
Claude Opus (Architect): High-level decisions, system design, complex reasoning. When I need something figured out, Opus thinks it through.
Claude Sonnet (Executor): Day-to-day coding, research, content creation. The workhorse that gets things done.
Claude Haiku (Housekeeper): Mechanical tasks, file operations, status checks. Fast, cheap, reliable for grunt work.
This isn't theory. Yesterday I ran 13 sub-agents simultaneously:
- 1 Opus architecting the CPMS planning system
- 7 Sonnets generating project issues from research
- 5 Haikus organizing files and pushing commits
Total extra cost: $0.

The subscription model changed everything about how I think about AI costs.
Subscription vs API: The Math
Most people use API calls because tutorials teach API calls. This is backwards economics.
API pricing reality:
- Claude Opus: $15 per million input tokens
- Heavy orchestration: 500K+ tokens per day easy
- Monthly cost: $225+ just for tokens
Subscription reality:
- Claude Pro: $20/month for personal use
- Claude Max: $100-200/month for high usage
- Unlimited usage within fair use
I hit the API equivalent of $7,000/month in tokens on my $200 Max subscription. The savings fund my entire infrastructure.
Reddit analysis shows subscriptions are 36x cheaper for power users. I verified this with my own usage data.
Start with API for experimentation. Switch to subscription when you're serious.
Local LLMs: The Hybrid Approach
I also run local models for specific tasks:
Llama 3.1 405B on a rented GPU cluster for sensitive research. Costs more than Claude but keeps data fully private.
Mistral 32B on my local GPU for simple tasks. Great for file processing, data extraction, repetitive work.
Qwen 2.5 Coder for code completion. Runs locally, integrates with my IDE, surprisingly good for smaller changes.
Local models require serious hardware. 32B parameter models need 24GB+ VRAM. 405B models need multiple H100s or cloud GPU clusters.
But the control is worth it. When I'm processing sensitive client data, it never leaves my infrastructure.
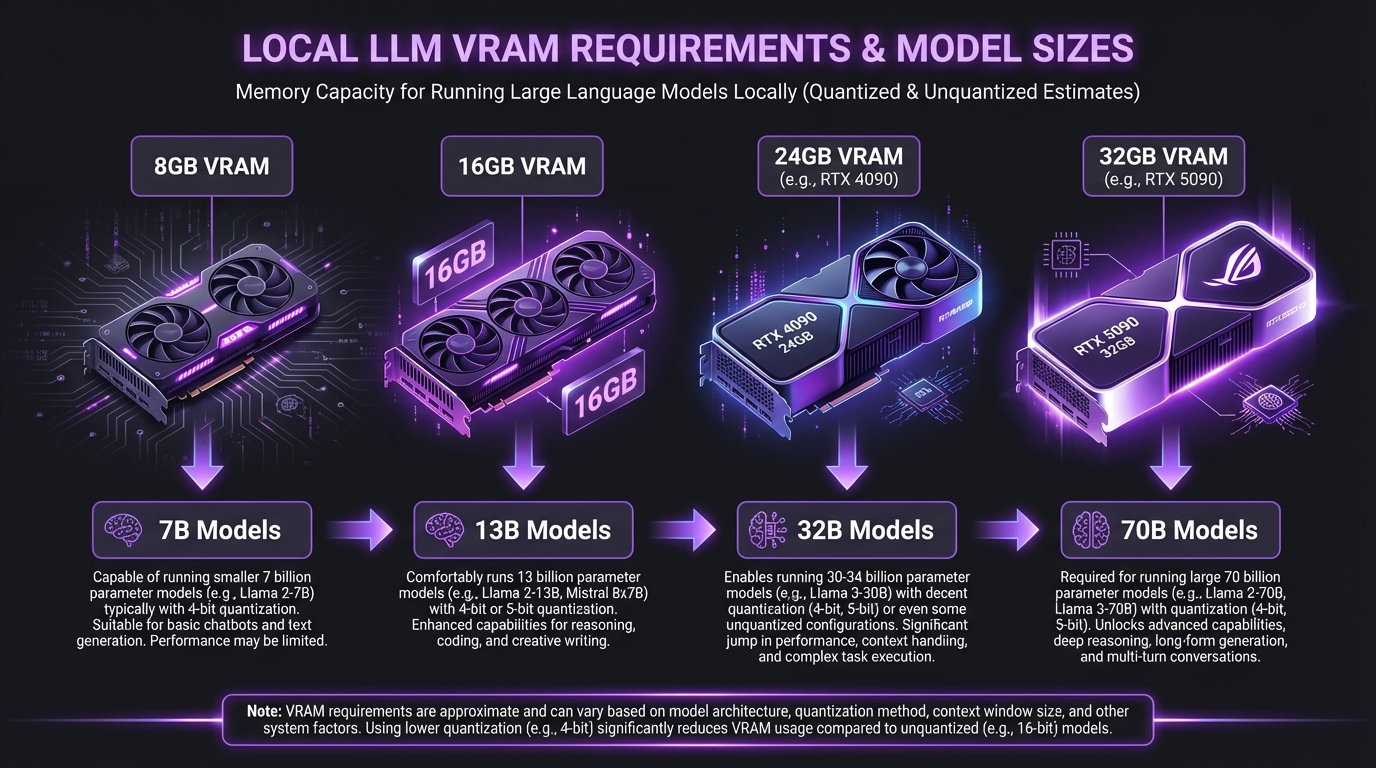
The hybrid approach works: cloud for complex reasoning, local for privacy and speed.
Don't Start with the Cheapest
Biggest mistake I see: people start with GPT-3.5 or Gemini Flash because they're cheap.
Then they spend weeks fighting model limitations instead of building their actual product.
I did this. Wasted a month trying to make cheap models do complex orchestration. The false economy cost me more than just using Opus from day one.
Start with the smartest model that can handle your task. Optimize down later when you understand the patterns.
Claude Opus 4.6 and GPT-5.2 are the current leaders for reasoning-heavy tasks. Use them for your orchestrator. Use cheaper models for the workers.
Model Rankings That Actually Matter
Forget the benchmarks. Here's what works for real orchestration:
Best orchestrators (complex reasoning):
- Claude Opus 4.6 - Best at coordinating multiple agents
- GPT-5.2 - Good reasoning, better tool use
- Claude Sonnet 4 - Solid middle ground
Best workers (execution):
- Claude Sonnet 4 - Fast, reliable, good at following instructions
- GPT-4o - Strong coding, decent speed
- Gemini Pro - Good for research, better at web tasks
Best housekeepers (mechanical tasks):
- Claude Haiku 4.5 - Ultra-fast, cheap, surprisingly capable
- GPT-4o Mini - Decent speed, very cheap
- Gemini Flash - Fast inference, good for simple operations
I've tested them all in production. These rankings come from running real orchestras, not benchmark scores.
The Open Source Gap Closed
December 2025 changed everything for local models.
The gap between frontier cloud models and open source models dropped to 0.3 percentage points on reasoning benchmarks. Llama 4.1, Qwen 3.0, and DeepSeek V3 are genuinely competitive.
For many tasks, local models are now good enough.
But "good enough" isn't the question for orchestration. The question is: what's the right tool for the job?
Use Claude Opus when you need the absolute best reasoning. Use Llama 405B when you need that same reasoning but with full data control. Use Haiku when you need speed and cost efficiency.
Match the model to the task, not your budget to the cheapest option.
Real Performance Data
Let me show you actual numbers from my orchestras:
Deep Research Orchestra (46 sources, 23,000 words):
- Opus orchestrator: 2.3M tokens, 47 minutes
- 5 Sonnet workers: 8.7M tokens combined, parallel execution
- API cost equivalent: ~$340
- Subscription cost: $0 extra
Code Shipping Orchestra (4 repos, 73 files changed):
- Opus architect: 1.8M tokens, design decisions
- 3 Sonnet coders: 12.4M tokens combined, implementation
- 2 Haiku housekeepers: 0.9M tokens, file operations
- API cost equivalent: ~$425
- Subscription cost: $0 extra
Security Audit Orchestra (parallel analysis):
- 4 Sonnet agents auditing simultaneously
- 15.2M tokens total across 6 hours
- API cost equivalent: ~$228
- Subscription cost: $0 extra
The subscription model made me rethink everything about AI costs. Instead of optimizing for token efficiency, I optimize for result quality.
Platform-Specific Optimizations
Different platforms have different model strengths:
OpenClaw: Excellent Claude integration, MCP support, good for complex orchestration
CrewAI: 40% faster to production, great for standardized workflows
LangGraph: Best for complex state machines, good for multi-step reasoning
AutoGen: Strong multi-agent conversations, good for collaborative tasks
I use OpenClaw because it gives me the most control over model selection and orchestration patterns. But the platform matters less than picking the right models for each role.
Future-Proofing Your Choice
Models change fast. GPT-5 will drop this year. Anthropic keeps shipping new Claude versions. Open source models keep improving.
Build your orchestration logic to be model-agnostic. Use platforms that support multiple providers. Write your prompts to work across different models.
I've switched orchestrators 3 times in the last year. Each time took 2 hours, not 2 weeks, because I built for flexibility.
My Recommendation Stack
For anyone starting their first AI orchestra:
- Orchestrator: Claude Opus (subscription) — Best reasoning, worth the cost
- Workers: Claude Sonnet (subscription) — Reliable, fast, good at everything
- Housekeepers: Claude Haiku (subscription) — Cheap, fast, surprisingly capable
- Local backup: Qwen 2.5 Coder (self-hosted) — For sensitive tasks
Start simple. Scale smart. Optimize when you understand your patterns.
The conductor makes the orchestra. Choose yours carefully.
Sources & Inspiration
- Claude Subscriptions 36x Cheaper Analysis — Community cost breakdown showing subscription vs API savings
- Top LLMs 2025 Comparison — Claude Opus 4.6 and GPT-5.2 lead intelligence rankings
- Ultimate AI Models Comparison — GPT-5 leads in creativity and intelligence
- Claude Pricing Guide — API costs vs Pro subscription analysis
- Local LLM Hardware Requirements — RTX 4060 8GB handles 7-8B models in Q4_K_M
- 24GB GPU Deployment Guide — RTX 4090/3090 for 32B parameters optimization
- LLM Comparison December 2025 — Open source gap closed to 0.3 percentage points
Previously in this series:
- Part 1: Setting Up Your Stage
- Coming next: Part 3: Building the Stage
More from “Build Your Own Orchestra”
Setting Up Your Stage: Infrastructure for AI Agent Orchestration
Your agents need their own home. Here's how I built mine.
Building the Stage: Platforms and Tools for AI Orchestration
The platform you choose determines what's possible. Here's what actually works.
Your First Orchestra: From Solo Act to Multi-Agent Symphony
Stop drowning in single-agent chaos. Here's how I built my first multi-agent workflow that saved me 4 hours a day.
The Compound Effect: From One Agent to an AI Organization
How I scaled from 1 agent to 13+ orchestras running simultaneously, and why memory is everything.