
The Translation Test: Why I Built What Others Just Theorize About
By Conny Lazo
Builder of AI orchestras. Project Manager. Shipping things with agents.
Code is about to cost nothing, and knowing what to build is about to cost you everything.
That's how Nate B. Jones opened his latest video, and it resonated immediately — not because I'm a translation or future-of-work expert, but because I'd stumbled into this truth while building something for myself.
A few weeks ago, I built Text Grand Central — an AI-powered book translation tool. Not because I'm a linguist or because I saw a market opportunity, but because I had a specific problem: I wrote a book in English and wanted to translate it into French, German, Portuguese, and Spanish. Getting quotes from human translators? Per language, per book — it would have cost me my eyeballs. We're talking thousands per language, months of back-and-forth, and no guarantee they'd nail the nuance.
What happened next changed how I think about the future of work — and I'm sharing it as a builder's field report, not as industry analysis.
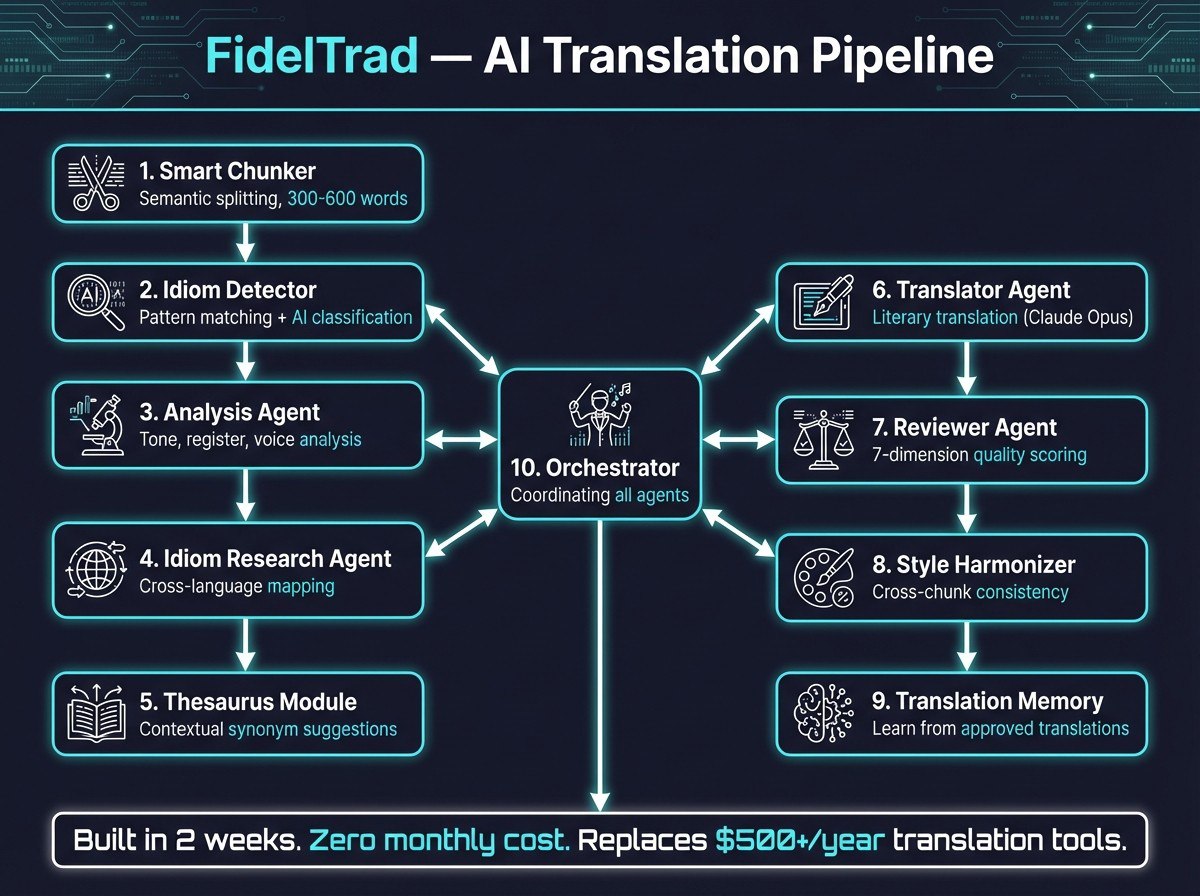
The Translation Reality Check
Here's what I discovered building Text Grand Central: AI didn't eliminate the need for human translators. It elevated what human judgment looks like.
My system runs on Next.js with Claude API integration, orchestrating three distinct AI models—Claude Opus 4.6 for complex literary passages, Sonnet 4 for technical content, and Haiku 4.5 for straightforward text. The architecture handles 32GB of contextual memory on my Pop!_OS workstation, processing entire books while maintaining narrative consistency across chapters.
But here's what I observed in the output: by volume, the AI handles roughly 90% of the translation work — the other 10% is specification, context-setting, and judgment calls. That ratio is based on how much text needs human correction, not total time invested. If you count setup, training the workflow, debugging edge cases, and quality review, the human contribution is much higher — it just happens earlier in the pipeline rather than sentence by sentence.
I don't translate anymore. I specify. I define tone, context, and cultural nuances. I catch when the AI mistranslates a technical term or misses a cultural reference. I architect the multi-agent workflow that determines which model handles which type of content.
Sound familiar? It should. It's exactly what Nate B. Jones describes as the shift from production to specification work.
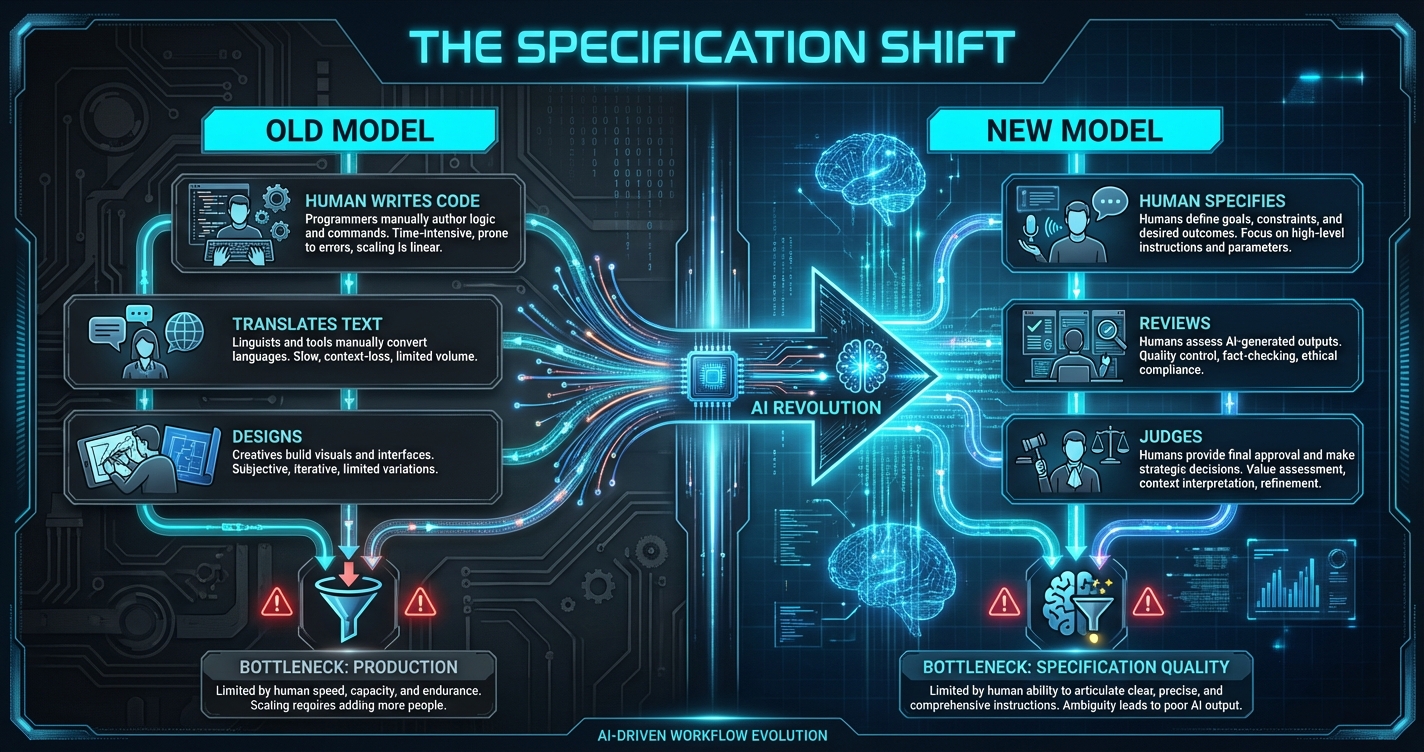
The Broader Pattern Nate Identified
In his video, Nate points to translation as the canary in the coal mine for all knowledge work. He references François Chollet's framework: when AI achieves near-perfect task capability, human roles transform rather than disappear. The Bureau of Labor Statistics still projects modest growth for translation jobs despite AI reaching human-level translation capability.
But Nate goes deeper. He identifies two distinct classes emerging across all knowledge work:
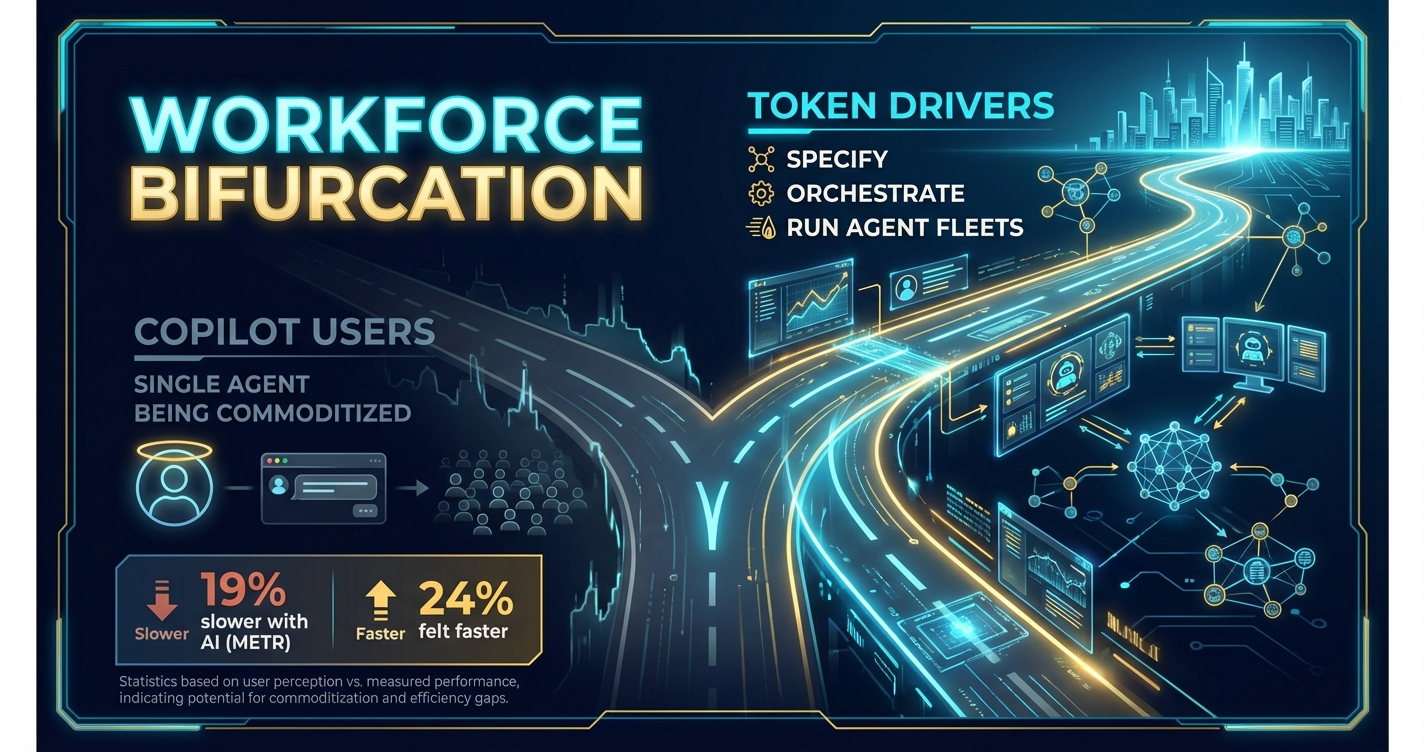
High-value "token drivers" who specify precisely, architect systems, and manage agent fleets. They're seeing explosive revenue per employee—companies like Cursor at $16 million per employee, Midjourney at $200 million with just 11 people.
Low-leverage workers using single-agent workflows, getting commoditized as entry-level postings drop by two-thirds and 70% of hiring managers say AI can handle intern-level work.
I Built What Nate Theorizes About
Here's what makes Text Grand Central more than just a translation tool—it's proof of Nate's thesis in action:
Multi-agent orchestration: My system runs what Nate calls an "agent fleet." Three Claude models with specialized roles, coordinated by human specification. It's not one AI doing everything; it's multiple AIs doing what they're best at, directed by human judgment.
The token driver model: I went from facing thousands per language and months of waiting to processing a full book translation in weeks for a fraction of the cost. But the real value isn't savings — it's that I can now translate into four languages simultaneously, something that was previously economically impossible for an independent author.
Specification as the scarce resource: The hardest part of building Text Grand Central wasn't the technical architecture. It was learning to specify intent precisely enough that AI agents could execute reliably. "Make it sound natural" isn't a specification. "Maintain the author's academic tone while simplifying technical jargon for a business audience" is.
This is the inversion Nate describes: when production costs collapse to zero, specification becomes everything.
The Dark Factory I'm Living In
What keeps me up at night—and gets me out of bed every morning—is realizing I'm already operating what METR's study calls a "dark factory." My translation pipeline runs with minimal human intervention. Three AI agents coordinate, make decisions, and produce output that's often better than what I could create manually.
But I'm not just observing this transformation—I'm orchestrating it. And that's the difference between thriving and surviving in the AI transition.
The data backs this up. Code Rabbit's analysis found AI-generated code produces 1.7x more logic issues than human code. The problem isn't AI capability—it's specification quality. When I write clear specifications for Text Grand Central's agents, they execute flawlessly. When I'm vague, they build the wrong thing perfectly.
The J-Curve We're All Riding
Here's where Nate's framework gets personally uncomfortable: we're in the trough of a productivity J-curve right now. Census Bureau research shows AI deployment initially reduces productivity by 1.3 percentage points, with some firms dropping 60 points before recovery.
I lived this. Text Grand Central's first month was brutal. The AI made translation errors that human translators never would. I spent more time fixing output than I would have writing from scratch. But once I learned to specify properly—to architect the multi-agent system and define clear success criteria—productivity exploded.
That's the pattern across knowledge work. The METR study found experienced developers are 19% slower with AI tools despite believing they're 24% faster. The disconnect isn't the technology—it's the specification skill gap.
The Skills That Actually Matter
Building Text Grand Central taught me that the future isn't about learning to code or mastering specific AI tools. It's about developing what engineers have spent 50 years perfecting: the ability to translate vague human intent into executable specifications.
Think in systems, not documents. Text Grand Central isn't a document generator—it's a system with inputs, rules, and validation criteria. Once specified, it runs autonomously and improves with feedback.
Make outputs verifiable. Every Text Grand Central translation includes confidence scores, alternative phrasings, and cultural context flags. I can measure quality objectively, not by vibes.
Audit for coordination overhead. Traditional translation workflows involved project managers, reviewers, and coordinators. Text Grand Central eliminates that entirely—the system coordinates itself based on specifications I defined once.
These aren't technical skills. They're thinking frameworks that work across any domain where AI is transforming production.
The Choice We All Face
Nate ends his video with a challenge: "The technology is not going to wait for organizations and individuals to catch up. We have to lean in and help each other."
He's right. But I'd go further: The window for choosing which side of the bifurcation you end up on is closing faster than most people realize.
I built Text Grand Central not because I'm smarter than anyone else, but because I treated AI as a system to architect rather than a tool to use. That mental shift—from "How can AI help me work faster?" to "How can I specify what AI should build?"—is what separates high-value token drivers from low-leverage workers getting commoditized.
From what I've seen building Text Grand Central, translation surfaced this dynamic early — possibly because AI's text capabilities matured faster there. But the broader pattern Nate identifies — that specification becomes the scarce resource as production costs collapse — seems to apply across knowledge work, even if the timeline and shape differs by domain.
Whether you're specifying a translation, a software feature, or a business strategy, the cognitive challenge looks similar: translating vague human intent into precise instructions that human or machine systems can execute. And the people who develop that skill — who can architect workflows and validate outputs against intention — seem to be capturing more value than those who don't.
What Are You Building With It?
I didn't set out to prove Nate B. Jones's thesis about the future of work. I just wanted to translate some books. But building Text Grand Central taught me that the AI revolution isn't coming—it's here. The only question is whether you're architecting it or being architected by it.
The translation test isn't about translation. It's about whether you can specify intent precisely enough that AI systems can execute it reliably. Whether you can think in systems, validate outputs, and orchestrate multiple agents toward a defined outcome.
If you can pass the translation test—if you can master specification as a core skill—the world is your oyster. If you can't, you're in for a rougher ride than most people expect.
What are you building with it?
Note: I'm not a linguist, translation professional, or future-of-work researcher. I'm a builder who made a translation tool to solve my own problem and drew some conclusions from the experience. This article reflects that journey — what I learned by doing, not domain expertise. If you're a translation professional and something here misrepresents how the industry works, I want to hear it.
Sources & Inspiration
- Nate B. Jones — "Code Is About to Cost Nothing" — The video that sparked this article, framing specification as the scarce resource in an AI-abundant world
- METR — Early 2025 AI-Experienced OS Dev Study — Found experienced developers 19% slower with AI tools despite believing they were 24% faster
- Code Rabbit — State of AI vs Human Code Generation Report — AI-generated code produces 1.7x more logic issues than human code
- IEEE Spectrum — AI Effect on Entry-Level Jobs — Entry-level postings dropped by two-thirds as AI handles intern-level work
- Census Bureau — AI Deployment and Productivity — AI deployment initially reduces productivity by 1.3 percentage points before recovery
- François Chollet's ARC Framework — Framework for understanding AI capability vs human intelligence